Apologies in advance for no reprex - apparently my clipboard is not available
Pretty sure I saw there was a way of combining rows after mutate/summarize
so that in the example below I could filter on pc >20 and end up with rows A, D and 'other' with a value of 23
I don't understand what you expect for output. what should have a value of 23 and what is 'other"?
Prose is a poor way to describe output, you should use R to build the output you expect as you did to show the input.
This is how to filter for pc >20
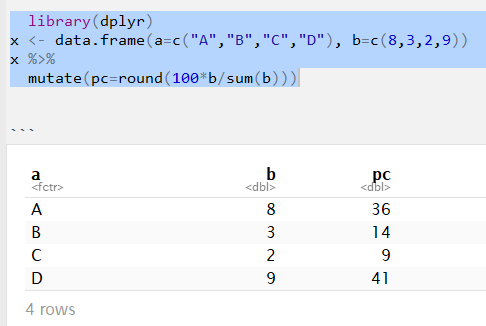
suppressPackageStartupMessages(library(dplyr))
x <- data.frame(a = c("A", "B", "C", "D"), b = c(8, 3, 2, 9))
x %>% mutate(pc = round(100*b/sum(b))) %>%
filter(pc > 20)
#> a b pc
#> 1 A 8 36
#> 2 D 9 41
It's a little tricky because column a of your data.frame is a factor
suppressPackageStartupMessages(library(dplyr))
x <- data.frame(a = c("A", "B", "C", "D"), b = c(8, 3, 2, 9))
# because column a is a factor "others" needs to be
# added so that value can be used in column a
levels(x$a) <- c(levels(x$a), "others")
x %>%
# do computation
mutate( pc = round(100*b/sum(b))) %>%
# add "others" row
rbind(data.frame(a = "others",
b = sum(filter(., pc <= 20)$b),
pc = sum(filter(., pc <= 20)$pc))) %>%
# keep others row regardless of pc value
filter(pc >20 | a == "others")
#> a b pc
#> 1 A 8 36
#> 2 D 9 41
#> 3 others 5 23
Another way to do this would be to group by the a variable and use mutate and case_when to create the labels, as following:
suppressPackageStartupMessages(library(dplyr))
x <- data.frame(a = c("A", "B", "C", "D"), b = c(8, 3, 2, 9))
x %>%
mutate(pc = round(100 * b / sum(b))) %>% # Compute %
group_by(a) %>%
mutate(type = case_when( # Create variable where
pc > 20 ~ as.character(`a`), # equal to `a` if `pc`> 20
TRUE ~ "Other") # otherwise as `Other`
) %>%
group_by(type) %>% # Group by new variable
summarise_if(is.numeric, sum) # Compute values
#> # A tibble: 3 x 3
#> type b pc
#> <chr> <dbl> <dbl>
#> 1 A 8.00 36.0
#> 2 D 9.00 41.0
#> 3 Other 5.00 23.0
Wondering if when you originally thought you’d seen a way of doing this before, you were perhaps remembering forcats::fct_lump or forcats::fct_other? They don’t quite apply to this case, but fct_other could be useful in the above solution if you have a lot more categories to lump in your real data.
That absolutely was what I meant.
I will use that for real-life examples with more categories
I currently only use fct_reorder() for charting purposes but there is a lot more to the forcats package
There’s nothing worse than that Twilight Zone feeling when you swear you remember reading something in the docs and now (cue creepy music) it has vanished!