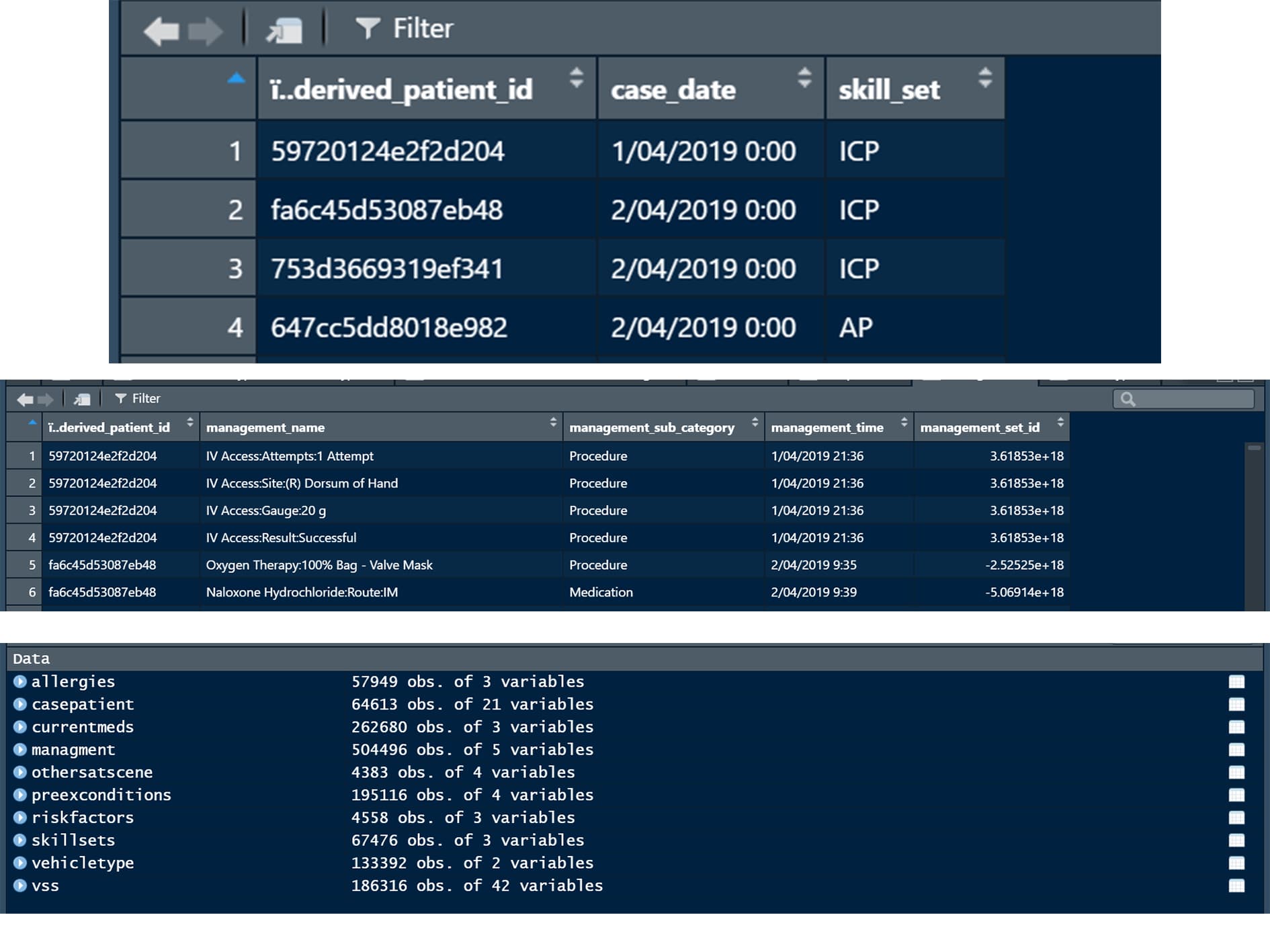
Each observation has a unique identifier that has been randomly hashed for anonmity, however is conistent between tables - however not all identifiers are on all tables. The order is also different.
What is the best way of combining just the variables of interest from seperate tables, while aligining them with their corresponding variables as appropriate.
For example, I may want to use 3 variables from casepatient, 1 from skillsets, 4 from vss but make sure that the same observation is not produced as two different observations.
And finally, because they are random the hashed identifiers are... random. They are the variable called ï..derived_patient_id on each table.
Thanks for posting. Before anything else, you'll need to establish what variables you need to qualify an observation as a unique observation. It sounds like you are most the way there with patient ids, but you may need to go a bit further. For example, can one patient id appear for several dates in the same table? If so, date is probably needed to get at unique variables. Once you have that, I would recommend using a join function from dplyr (such as inner_join) to merge all of your data frames into one cohesive dataset, then use dplyr::select to look at the variables you want to look at.
If you want to look at some code for how to do that, please provide a REPRoducible EXample, instructions for which can be found here.
I did some digging and it turns out that in some tables one pt id can be repeated.
An example is the vital signs table, where if multiple sets of VSS were done they are each reported as their own observation.
This immediately broke and became more than I could handle.
K.I.S.S!
casepatient %>%
inner_join(skillsets, by = "ï..derived_patient_id") %>%
inner_join(vehicletype, by = "ï..derived_patient_id") %>%
inner_join(managment, by ="ï..derived_patient_id") %>%
inner_join(preexconditions, by = "ï..derived_patient_id") %>%
inner_join(allergies, by = "ï..derived_patient_id") %>%
inner_join(currentmeds, by = "ï..derived_patient_id") %>%
inner_join(riskfactors, by = "ï..derived_patient_id") %>%
inner_join(vss, by = "ï..derived_patient_id") %>%
write_csv(path = "blah blah blah")
It ended up giving me a memory error when I just tried to make it intially, as its a huge dataframe. So easiest workaround was just to export as a .csv and go from there... I think!