I have a csv survey, it contains ethnicity.
I used gsub or aggregate to find the frequency but failed.
Please teach me how to clean this data to this following example:
American | 300
Indian | 100
Vietnamese | 60
thanks
Mark
I have a csv survey, it contains ethnicity.
I used gsub or aggregate to find the frequency but failed.
Please teach me how to clean this data to this following example:
American | 300
Indian | 100
Vietnamese | 60
thanks
Mark
Hi!
To help us help you, could you please prepare a reproducible example (reprex) illustrating your issue? Please have a look at this guide, to see how to create one:
Thanks.
However, I think mine is not an issue. It's I don't know how to do it. I hope to know learn how to clean it and extract the texts.
Thanks.
Mark
Well if you don't know how to do it, I think that is an issue for you, and in order for us to help you we need sample data on a copy/paste friendly format. (like is explained in the link I gave you).
Hi, andresrcs,
Sorry for my ignorance about the term.
I thought it means reproduce the process.
However, I tried the link you provided. I've encountered some issues as follow:
I've tried copy-paste from excel, but it wasn't allowed to paste with tipple.
I also tried others. Do you mind helping me understand my mistake?
Thanks.
Mark
Hard to know with the information you are providing, this is a nice blog post about datpasta that might be of help for you.
Another option is to share a link to your csv file so we can download it and try to help you.
I'm going to give you a small example of how to do this task, as long as you are able to read your data as a data frame, you can do something like this.
library(tidyverse)
# Sample data / you have to replace this by your actual dataset
sample <- data.frame(stringsAsFactors = FALSE,
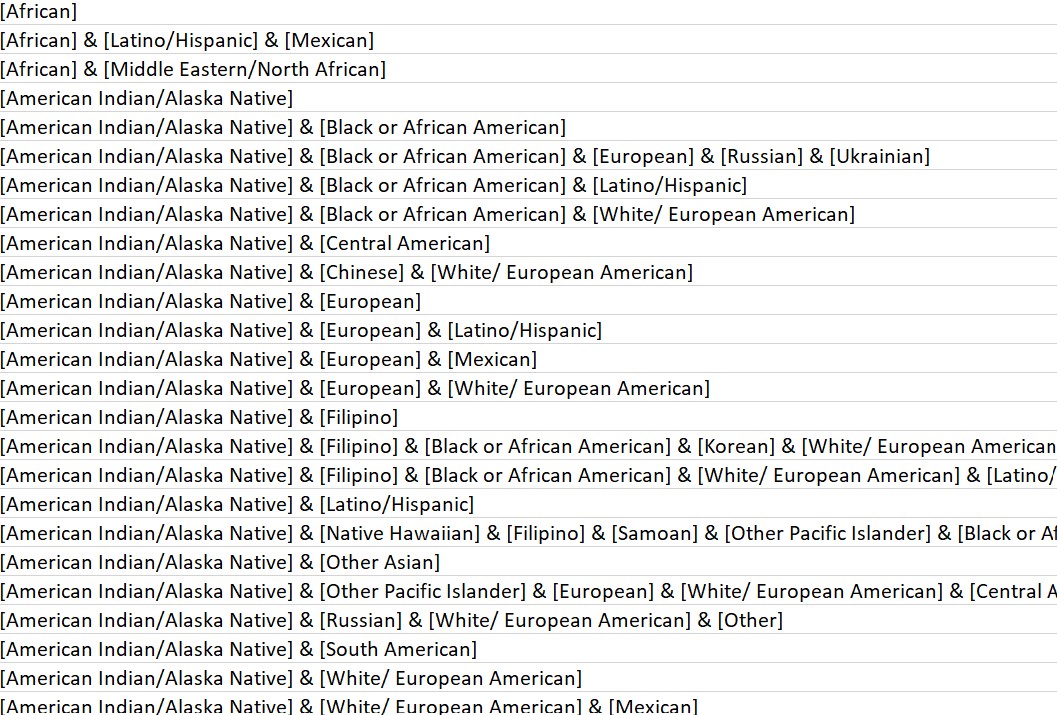
ethnicity = c("[African]", "[African] & [Latino/Hispanic] & [Mexican]",
"[African] & [Middle Eastern/North African]",
"[American Indian/Alaska Native]",
"[American Indian/Alaska Native] & [Black or African American]"))
sample %>%
separate_rows(ethnicity, sep = "\\s&\\s") %>%
mutate(ethnicity = str_remove_all(ethnicity, "[\\[\\]]")) %>%
count(ethnicity)
#> # A tibble: 6 x 2
#> ethnicity n
#> <chr> <int>
#> 1 African 3
#> 2 American Indian/Alaska Native 2
#> 3 Black or African American 1
#> 4 Latino/Hispanic 1
#> 5 Mexican 1
#> 6 Middle Eastern/North African 1
Created on 2019-10-08 by the reprex package (v0.3.0.9000)
Hi, andresrcs,
Sorry for the late reply. I was in the class.
Thanks for the example.
By the way, why is the difference between factor and list or data.table?
Do you mind recommending a site so that I can understand more?
Thanks.
Mark
I think I don't really understand your question, you are mentioning some object classes but I don't understand what is your doubt about them.
If you are looking for a basic introduction to R I think this online book is a good resource.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.