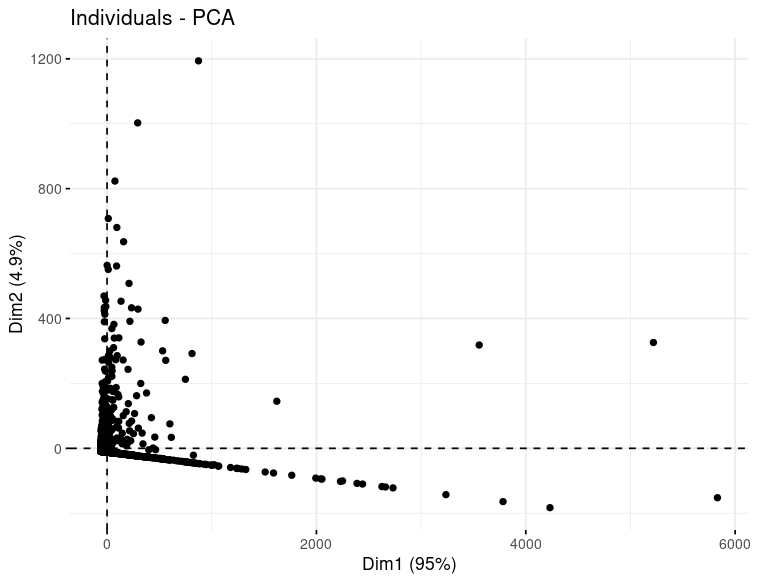
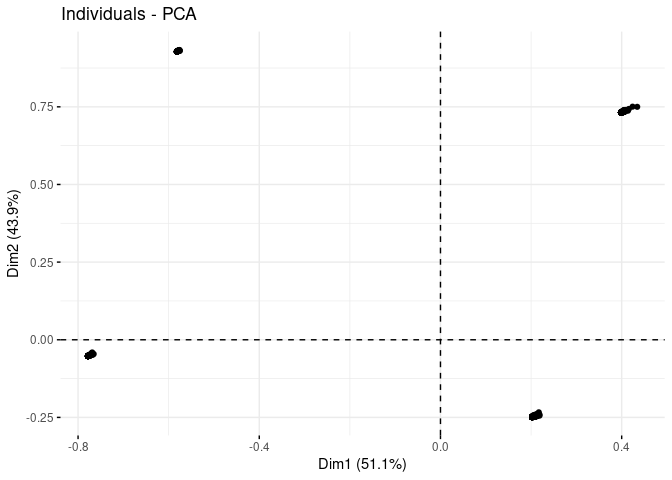
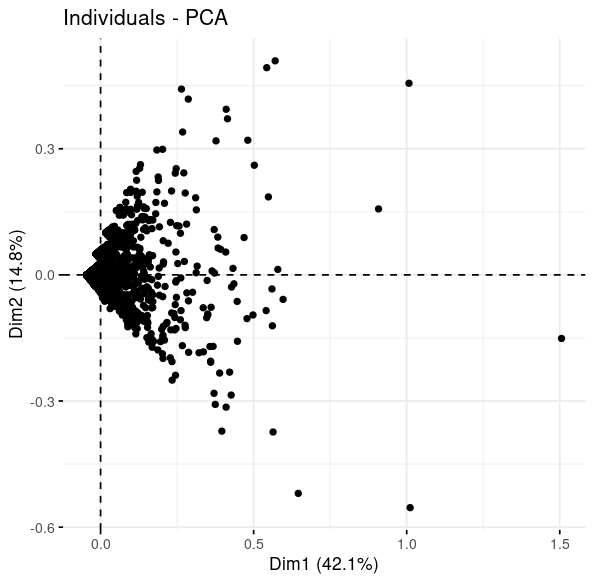
I have a data set that contains 2 binary variables and 7 continuous variables. I would like to cluster this data. After scaling my variables, I Initially I tried with kmeans but when looking at the results I noticed that the binary variables caused perfect separation among cluster groups which was unexpected.
After some research I read this post on SO.
I then gave PAM clustering a shot with a distance matrix. However, I get a very similar result as to when I initially tried with kmeans, the 2 binary variables seem to determine the clusters and everything else is just a side show.
Here's my data, a csv with 3,200 rows and disguised field names and scaled data.
Here's the steps to reproduce:
pacman::p_load(tidyverse, fpc, cluster)
cluster_data <- readr::read_csv('cluster_data.csv')
bool_cols <- cdata_selected |> select_at(vars(matches('Bool'))) |> ncol()
g.dist = daisy(cluster_data, metric = "gower", type = list(symm = 1:bool_cols)) # I think/hope that I'm telling daisy to treat the first twop columns as bools here
pc = pamk(g.dist, krange=2:10, criterion = "asw")
# get 4 clusters
pc$nc # 4
# summary of clusters:
cluster_data$cluster <- pc$pamobject$clustering
cluster_summary <- cluster_data |>
group_by(cluster) |>
summarise(
N = n(),
across(matches('Bool|Count'), mean, .names = 'Avg_{.col}')) |>
mutate_at(vars(-cluster), ~ round(., 4))
cluster_summary |> View()
# binary variables cause perfect seperation, expected some more mixing
cluster_data |>
group_by(cluster) |>
summarise(N = n(),
Bool1Total = sum(Bool1),
Bool2Total = sum(Bool2)
)
The data frame 'cluster summary' shows averages of each field by cluster. Then the last block just illustrates the separation of clusters along the binary variables:
cluster_data |>
group_by(cluster) |>
summarise(N = n(),
Bool1Total = sum(Bool1),
Bool2Total = sum(Bool2)
)
# A tibble: 4 × 4
cluster N Bool1Total Bool2Total
<int> <int> <dbl> <dbl>
1 1 1944 0 1944
2 2 518 518 518
3 3 663 0 0
4 4 149 149 0
I might expect some clusters to have a higher or lower proportion of the bool variables, but not 100% separation as I have just now.
While reading the SO post I linked to, it sounded like PAM clustering with a gowen matrix was the way to get around not being able to use binary variables in kmeans. But nonetheless, it seems that when I use PAM, I still get perfect separation along these variables.
Is this expected? Is my approach wrong? How can I best cluster this data set?