Hi, and welcome!
Please see the FAQ: What's a reproducible example (`reprex`) and how do I create one? Using a reprex, complete with representative data will attract quicker and more answers.
It's not needed for this, question, however. In addition, this is a good example of coming to understand R and unwind the questions.
To start, think of R as school algebra: f(x) = y.
R is all about functions. For any function f, such as hclust, there are one or more arguments x and a value (or result) y.
Looking at help(hclust), we see that its argument d is a dist object. (You'll find that everything in R is an object, whether it is as simple as a single integer
some_number <- 1
str(1)
#> num 1
Created on 2020-03-22 by the reprex package (v0.3.0)
or as complicated (or more!) as this portion of a lm linear regression model
fit <- lm(mpg ~ wt, data = mtcars)
str(fit)
#> List of 12
#> $ coefficients : Named num [1:2] 37.29 -5.34
#> ..- attr(*, "names")= chr [1:2] "(Intercept)" "wt"
#> $ residuals : Named num [1:32] -2.28 -0.92 -2.09 1.3 -0.2 ...
#> ..- attr(*, "names")= chr [1:32] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...
#> $ effects : Named num [1:32] -113.65 -29.116 -1.661 1.631 0.111 ...
#> ..- attr(*, "names")= chr [1:32] "(Intercept)" "wt" "" "" ...
#> $ rank : int 2
#> $ fitted.values: Named num [1:32] 23.3 21.9 24.9 20.1 18.9 ...
#> ..- attr(*, "names")= chr [1:32] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...
#> $ assign : int [1:2] 0 1
#> $ qr :List of 5
#> ..$ qr : num [1:32, 1:2] -5.657 0.177 0.177 0.177 0.177 ...
#> .. ..- attr(*, "dimnames")=List of 2
#> .. .. ..$ : chr [1:32] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...
#> .. .. ..$ : chr [1:2] "(Intercept)" "wt"
#> .. ..- attr(*, "assign")= int [1:2] 0 1
#> ..$ qraux: num [1:2] 1.18 1.05
#> ..$ pivot: int [1:2] 1 2
#> ..$ tol : num 1e-07
#> ..$ rank : int 2
#> ..- attr(*, "class")= chr "qr"
#> $ df.residual : int 30
#> $ xlevels : Named list()
#> $ call : language lm(formula = mpg ~ wt, data = mtcars)
#> $ terms :Classes 'terms', 'formula' language mpg ~ wt
#> .. ..- attr(*, "variables")= language list(mpg, wt)
#> .. ..- attr(*, "factors")= int [1:2, 1] 0 1
#> .. .. ..- attr(*, "dimnames")=List of 2
#> .. .. .. ..$ : chr [1:2] "mpg" "wt"
#> .. .. .. ..$ : chr "wt"
#> .. ..- attr(*, "term.labels")= chr "wt"
#> .. ..- attr(*, "order")= int 1
#> .. ..- attr(*, "intercept")= int 1
#> .. ..- attr(*, "response")= int 1
#> .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv>
#> .. ..- attr(*, "predvars")= language list(mpg, wt)
#> .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric"
#> .. .. ..- attr(*, "names")= chr [1:2] "mpg" "wt"
#> $ model :'data.frame': 32 obs. of 2 variables:
#> ..$ mpg: num [1:32] 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
#> ..$ wt : num [1:32] 2.62 2.88 2.32 3.21 3.44 ...
#> ..- attr(*, "terms")=Classes 'terms', 'formula' language mpg ~ wt
#> .. .. ..- attr(*, "variables")= language list(mpg, wt)
#> .. .. ..- attr(*, "factors")= int [1:2, 1] 0 1
#> .. .. .. ..- attr(*, "dimnames")=List of 2
#> .. .. .. .. ..$ : chr [1:2] "mpg" "wt"
#> .. .. .. .. ..$ : chr "wt"
#> .. .. ..- attr(*, "term.labels")= chr "wt"
#> .. .. ..- attr(*, "order")= int 1
#> .. .. ..- attr(*, "intercept")= int 1
#> .. .. ..- attr(*, "response")= int 1
#> .. .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv>
#> .. .. ..- attr(*, "predvars")= language list(mpg, wt)
#> .. .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric"
#> .. .. .. ..- attr(*, "names")= chr [1:2] "mpg" "wt"
#> - attr(*, "class")= chr "lm"
Created on 2020-03-22 by the reprex package (v0.3.0)
This bring us to the next question: what's a dist?
There's help(dist) to answer that.
This function computes and returns the distance matrix computed by using the specified distance measure to compute the distances between the rows of a data matrix.
Its argument x is
a numeric matrix, data frame or [another] "dist" object
The hidden clue is numeric matrix A matrix is an object that can contain either character objects or numeric objects, but not both. While a data frame object can contain both, the limitation to numeric matrix objects alters to the operations that will be done one the contents, which are numeric computations.
This is more clearly shown by the method argument
the distance measure to be used
Although there are distance metrics within natural language processing tools for characters, for example, we don't ordinarily think of an obvious way to calculate the distance from "Utah" to "selenium", for example.
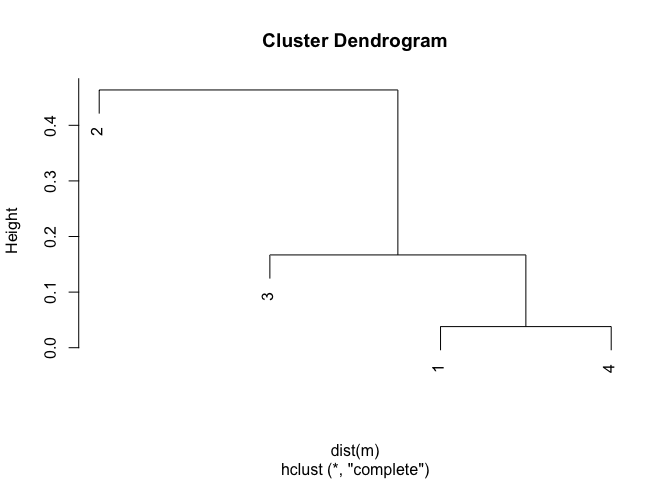
This is a long-winded way to point to the answer: In example1, only x and y are numeric.
Putting it all together (in compact form)
x <- c(0.8835, 0.4574, 0.764, 0.9119)
y <- c(-0.1976,-0.3141,-0.3001,-0.2228)
m <- as.matrix(cbind(x,y))
plot(hclust(dist(m)))
Created on 2020-03-22 by the reprex package (v0.3.0)