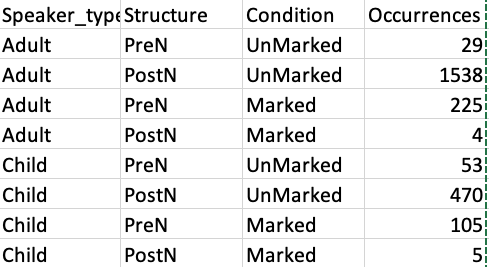
Hi Grey,
The tutorial is great and I am getting appropriate results. I have a question about poisson as part of glm.
It says to add family = poisson to the model to assume that the variables are independent form one another. In my case they are not as UnMarked context should yield more PreN structures and vice versa. So do I use it or not?
I ran models with both and I get more realistic results if I exclude the poisson. Like so:
Call:
glm(formula = Freq ~ Speaker.type + Structure + Context, data = ItAll.df)
Deviance Residuals:
1 2 3 4 5 6 7 8
145.00 -99.25 -9.75 -36.00 -90.25 44.50 -45.00 90.75
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 226.00 81.13 2.786 0.0495 *
Speaker.typeChild -53.25 81.13 -0.656 0.5474
StructurePostN -123.75 81.13 -1.525 0.2019
ContextMarked -124.75 81.13 -1.538 0.1989
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 13163.12)
Null deviance: 120077 on 7 degrees of freedom
Residual deviance: 52652 on 4 degrees of freedom
AIC: 103.04
Number of Fisher Scoring iterations: 2
It shows how the differences are not significant, but it is a plausible explanation.
However, when it is ran with family=poisson all of the comparisons are significant at the highest level, which I think is unlikely.
Call:
glm(formula = Freq ~ Speaker.type + Structure + Context, family = poisson,
data = ItAll.df)
Deviance Residuals:
1 2 3 4 5 6 7 8
1.6777 -6.7330 0.0878 -0.6918 -4.2241 7.0066 -3.7895 6.5545
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.82782 0.05265 110.686 <2e-16 ***
Speaker.typeChild -0.74096 0.08724 -8.493 <2e-16 ***
StructurePostN -2.33598 0.14385 -16.239 <2e-16 ***
ContextMarked -2.37809 0.14638 -16.246 <2e-16 ***
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 1208.64 on 7 degrees of freedom
Residual deviance: 172.89 on 4 degrees of freedom
AIC: 219.72
Number of Fisher Scoring iterations: 6
So, I ahve decided to go with the model without poisson. However, as I went further eith the anlysis and when the degrees of freedom need to be extracted. When I do that with the mod0 (without poisson), the result is 0:
pchisq(deviance(mod0), df = df.residual(mod0), lower.tail = F)
[1] 0
Which makes me have some doubts on the model. Then I tried running it with the model in which I included family=poisson (modPoiss) and there is a more realistic number (I guess):
pchisq(deviance(modPoiss), df = df.residual(modPoiss), lower.tail = F)
[1] 2.50456e-36
Thus, i am really unsure what is the correct way to procede with these data. Do you have any insight on that?
Thank you!
Marta