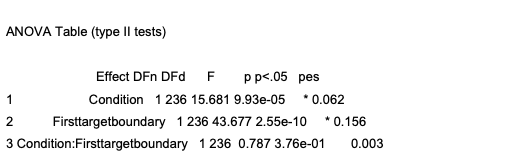
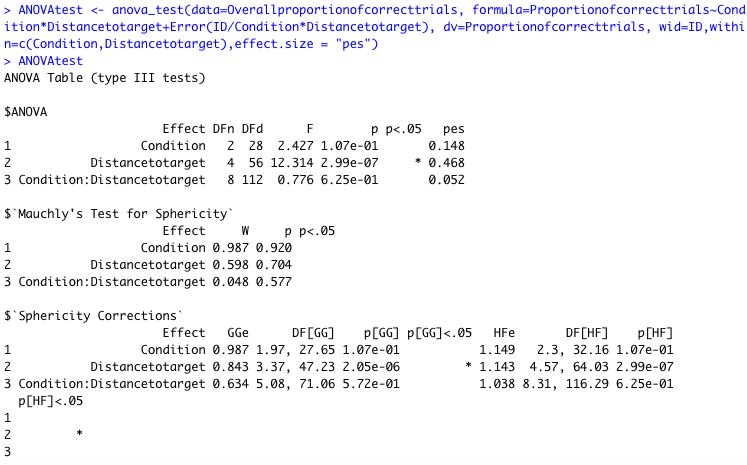
Hmmm. I tested by working an example of a repeated measures analysis and in my case the result was I did get sphericity check info by doing as I asked you to do. How can we confirm that your analysis is a repeated measures one ?
Does your data include observations on subjects repeated at different times ? If so some combination of subject id and time of the measurement should be unique, but this wasn't found in your data?
@nirgrahamuk yes, each subject is measured at 5 different distances, across 3 different speeds: and thus speed and distance are the within-subject variables, hence why I grouped by Condition (speed) and Firsttargetboundary (distance)
Which is why I am confused...
I think it is because some combinations produce the same value for the dependent variable:
Can you double check the actual combinations of these by using group_by() and count() on your data to show that condition and firsttargetboundary are unique and that there are not 75 non unique combinations?
I don't know your column order. Which columns are condition and firsttargetboundary?
What you show is completely duplicated so if it contains both cars, this is example of non unique. Shouldn't they be different in at least one of the two variables we are discussing?
So, you need to check your data pipeline from the earliest point you got your data to its present construction did a mistake cause duplicates ? Or is it an issue with the original data you sourced. If so simply deduoing must be considered. This might not be so bad if the data is entirely duplicated