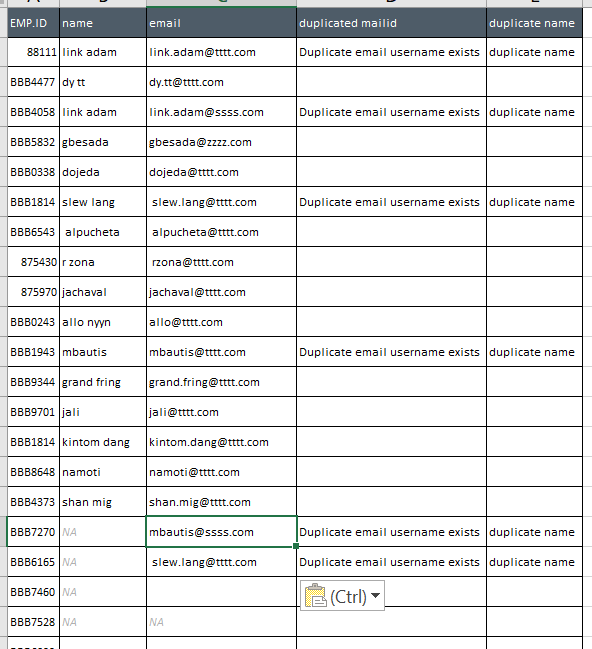
I have many records of data for email, now I want to check if I have duplicate names with same mail id and check if duplicate names exist before @ in email . i am trying below approach but not working for me. also I have NA and blank cells i also want to ignore those.
first I want to check if another mail ID exist with the same name. second i want to check if there is duplicate names exist in mail column (for example name in kling.mark@tttt.com if we have another mail id with kling mark)
df <- data.frame(EMP.ID = c(88111,"BBB4477","BBB4058","BBB5832","BBB0338","BBB1814","BBB6543",875430,875970,"BBB0243","BBB1943","BBB9344","BBB9701","BBB1814","BBB8648","BBB4373","BBB7270","BBB6165","BBB7460","BBB7528","BBB6092"),
name = c("link adam","dy tt","link adam","gbesada","dojeda","slew lang"," alpucheta","r zona","jachaval","allo nyyn","mbautis","grand fring","jali","kintom dang","namoti","shan mig","NA","NA","NA","NA",""),
email = c("link.adam@tttt.com","dy.tt@tttt.com","link.adam@ssss.com","gbesada@zzzz.com","dojeda@tttt.com"," slew.lang@tttt.com"," alpucheta@tttt.com"," rzona@tttt.com","jachaval@tttt.com","allo@tttt.com","mbautis@tttt.com","grand.fring@tttt.com","jali@tttt.com","kintom.dang@tttt.com","namoti@tttt.com","shan.mig@tttt.com","mbautis@ssss.com"," slew.lang@tttt.com","","NA",""))
Email= "email"
Name = "name"
valuesToIgnore <- c("", NA)
df <- df %>% mutate(`duplicate mailid` = ifelse(
duplicated(stringr::str_extract(Email, "([^@]+)")) &
!is.na(Email) &
nchar(as.character(Email)) > 0,
"Duplicate mail exist", ""
))
indicesOfAtSymbol <- unlist(gregexpr(pattern='@',Email))
namesFromEmails <- substr(Email,1, indicesOfAtSymbol-1)
df <- df %>% mutate(`duplicate name`= ifelse(duplicated(namesFromEmails, incomparables=valuesToIgnore),"duplicate name",""))
or if there is any other solution please help.
the output be like