I'm trying to get the links for the 2 tables in this webpage:
https://www.ipdb.org/lists.cgi?puid=43799&browser=1694266618&list=top300
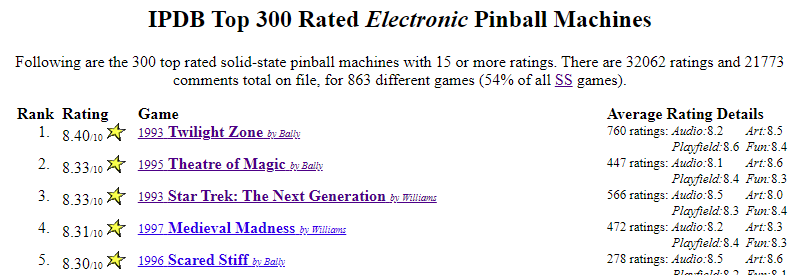
For some reason neither css selector or xpath seems to pull the tables so I've had to first pull the tables into a list, then extract each. That's got me the tables. But I can't get the links. I've tried various combinations of selector. If I include the 'a' part of the selector I get nothing; it's as if rvest can't see the links on this page. Or, more likely, I'm doing something wrong.
My code is below. Any help will be greatly appreciated because I've run out of ideas.
url <- "https://www.ipdb.org/lists.cgi?anonymously=true&list=top300"
download.file(url, destfile = 'machines_top_300.html')
page <- read_html("machines_top_300.html")
# put the 3 tables into a list
top_300_tables <- page %>%
html_nodes(xpath = "//table[.//th[contains(., 'Rank')]]")
# Get the table for the electronic machines (list item 2)
machines_top_300_electronic <-
top_300_tables[2] %>%
html_table(fill = TRUE) %>%
as.data.frame() %>%
mutate(Category = "Electronic")
# Get the hrefs for the electronic machines
machines_top_300_electronic_links <-
top_300_tables[2] %>%
html_nodes('tr > td:nth-child(3) > a') %>%
html_attr('href')