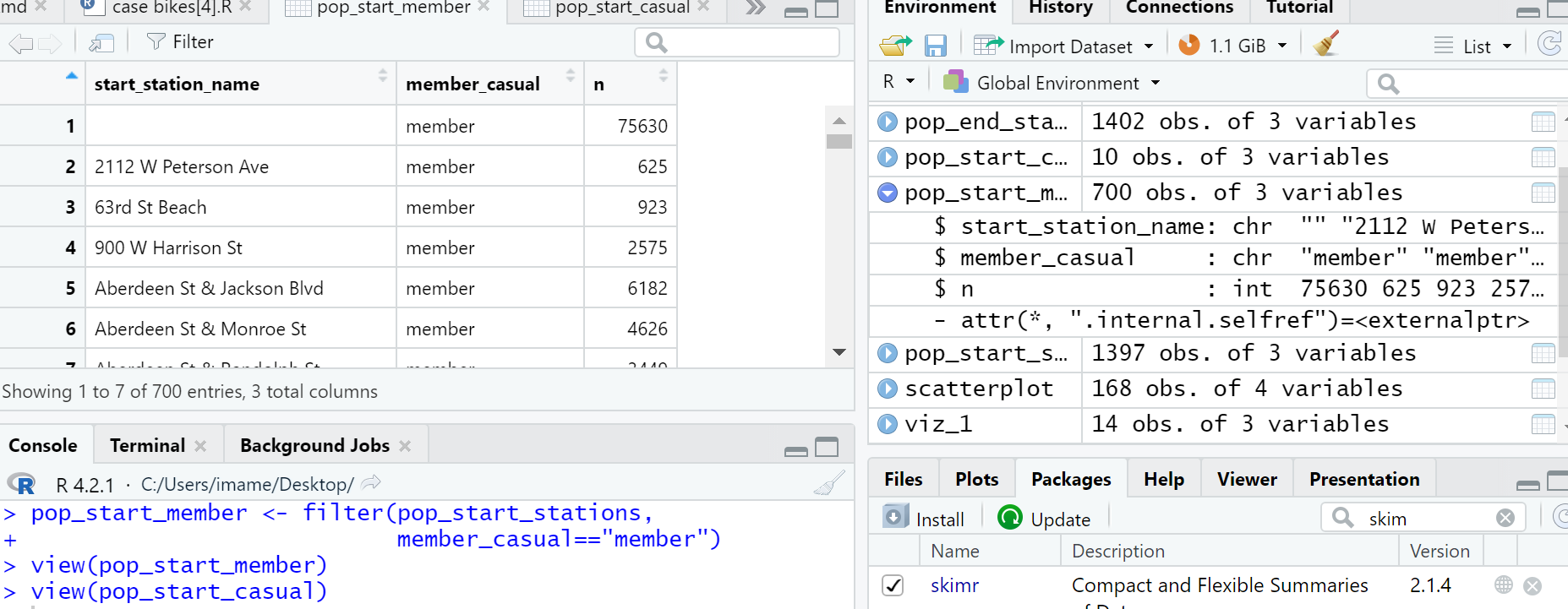
Hi everyone. I used
bike_rides <- janitor::remove_empty(bike_rides,which = c("cols"))
bike_rides <- janitor::remove_empty(bike_rides,which = c("rows"))
and
bike_rides <- drop_na(bike_rides) to remove empty spaces but there are still null cells. should I use another additional function to remove them also? because remove_empty and drop_na haven't removed them
I created an additional df with the top 10 popular stations (pop_start_casual) and when I run head it shows one empty chr cell with no name of the station, however,
when I visualize, there are 10 stations and not 9 like in df.
structure(list(ride_id = c("87BD0A8EA5A32570", "24341A8FAEE386F7",
"4283B31CE989D479", "C8E4240E1B632BBA", "9D5BFF5B0C04D47F", "AB31418818EA94C8",
"946A1DB8348B4B9B", "24AFB4228EF3818B", "A92CAF8151A36DBF", "39772A41D9C87C83"
), rideable_type = c("docked_bike", "electric_bike", "docked_bike",
"electric_bike", "docked_bike", "docked_bike", "docked_bike",
"docked_bike", "docked_bike", "docked_bike"), started_at = structure(c(1598108198,
1602799093, 1588528522, 1600633940, 1595518952, 1594405460, 1590768057,
1592049184, 1606201093, 1592505360), tzone = "UTC", class = c("POSIXct",
"POSIXt")), ended_at = structure(c(1598109882, 1602800578, 1588530184,
1600634322, 1595519133, 1594405655, 1590772439, 1592050870, 1606201372,
1592506655), tzone = "UTC", class = c("POSIXct", "POSIXt")),
start_station_name = c("Halsted St & Clybourn Ave", "Dearborn St & Erie St",
"Greenwood Ave & 47th St", "Clark St & Grace St", "Orleans St & Merchandise Mart Plaza",
"Damen Ave & Pierce Ave", "Columbus Dr & Randolph St", "Clark St & Schreiber Ave",
"Greenview Ave & Diversey Pkwy", "Kingsbury St & Erie St"
), start_station_id = c(331L, 110L, 252L, 165L, 100L, 69L,
195L, 453L, 319L, 74L), end_station_name = c("Clark St & Leland Ave",
"LaSalle St & Illinois St", "Lake Park Ave & 56th St", "Clark St & Wellington Ave",
"Sedgwick St & Huron St", "Damen Ave & Thomas St (Augusta Blvd)",
"Columbus Dr & Randolph St", "Chicago Ave & Sheridan Rd",
"Lincoln Ave & Roscoe St", "Broadway & Cornelia Ave"), end_station_id = c(326L,
181L, 345L, 156L, 111L, 183L, 195L, 603L, 230L, 303L), start_lat = c(41.909668,
41.894204, 41.8098, 41.9508371666667, 41.888243, 41.909396,
41.8847, 41.999252, 41.932589, 41.893808), start_lng = c(-87.648128,
-87.6292258333333, -87.5994, -87.6591698333333, -87.63639,
-87.677691, -87.6195, -87.671377, -87.665936, -87.641697),
end_lat = c(41.967096, 41.8906896666667, 41.7932, 41.9365458333333,
41.894666, 41.901315, 41.8847, 42.050491, 41.94334, 41.945529
), end_lng = c(-87.667429, -87.631892, -87.5878, -87.6476191666667,
-87.638437, -87.677409, -87.6195, -87.677821, -87.67097,
-87.646439), member_casual = c("member", "casual", "casual",
"member", "member", "member", "casual", "casual", "member",
"member"), ride_length = c(28.07, 24.75, 27.7, 6.37, 3.02,
3.25, 73.03, 28.1, 4.65, 21.58), start_hr = c(14L, 21L, 17L,
20L, 15L, 18L, 16L, 11L, 6L, 18L), day_of_week = structure(c(7L,
5L, 1L, 1L, 5L, 6L, 6L, 7L, 3L, 5L), levels = c("Sunday",
"Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"
), class = c("ordered", "factor")), month = structure(c(8L,
10L, 5L, 9L, 7L, 7L, 5L, 6L, 11L, 6L), levels = c("January",
"February", "March", "April", "May", "June", "July", "August",
"September", "October", "November", "December"), class = c("ordered",
"factor")), date = structure(c(18496, 18550, 18385, 18525,
18466, 18453, 18411, 18426, 18590, 18431), class = "Date"),
day = c("22", "15", "03", "20", "23", "10", "29", "13", "24",
"18"), year = c("2020", "2020", "2020", "2020", "2020", "2020",
"2020", "2020", "2020", "2020")), row.names = c(NA, -10L), class = c("data.table",
"data.frame"), .internal.selfref = <pointer: 0x0000021b875589c0>)