Use spec() to retrieve the full column specification for this data.
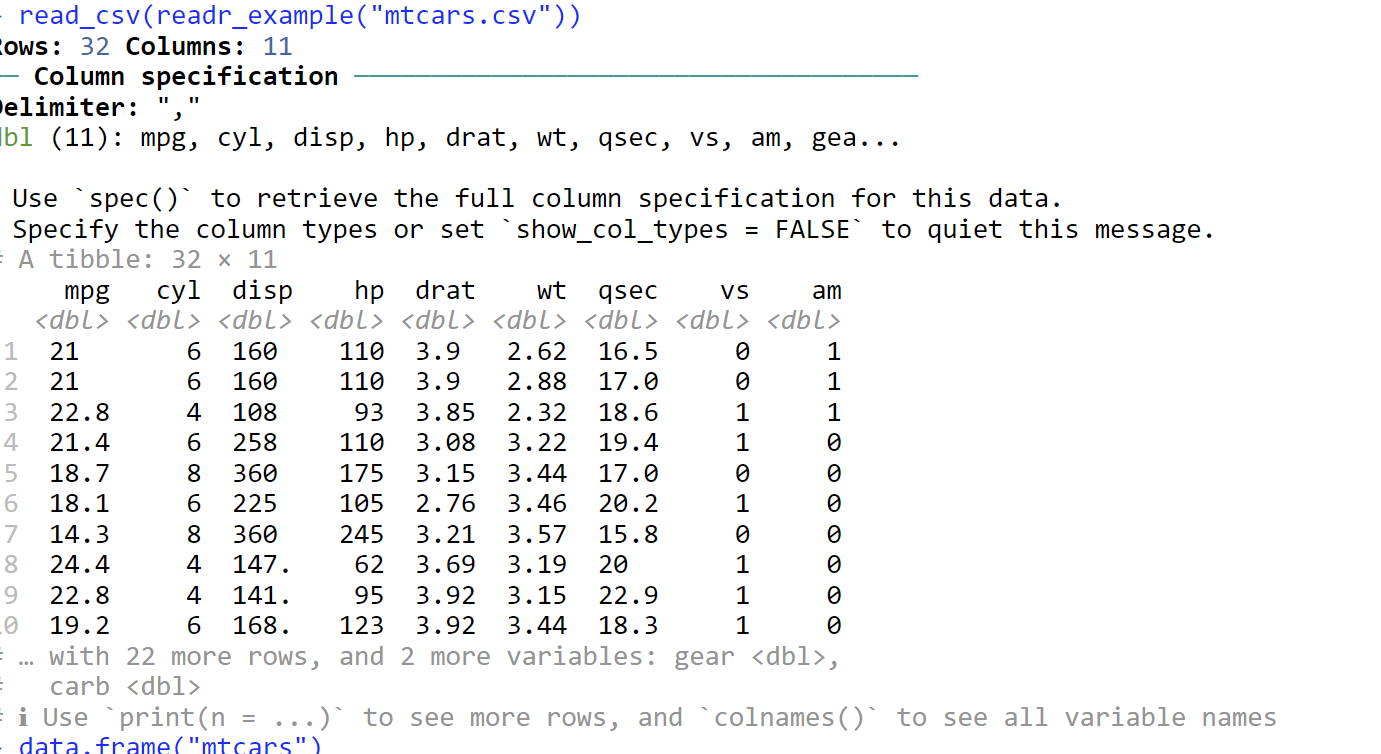
Type read_csv(readr_example("mtcars.csv")) %>% spec()
The result will be
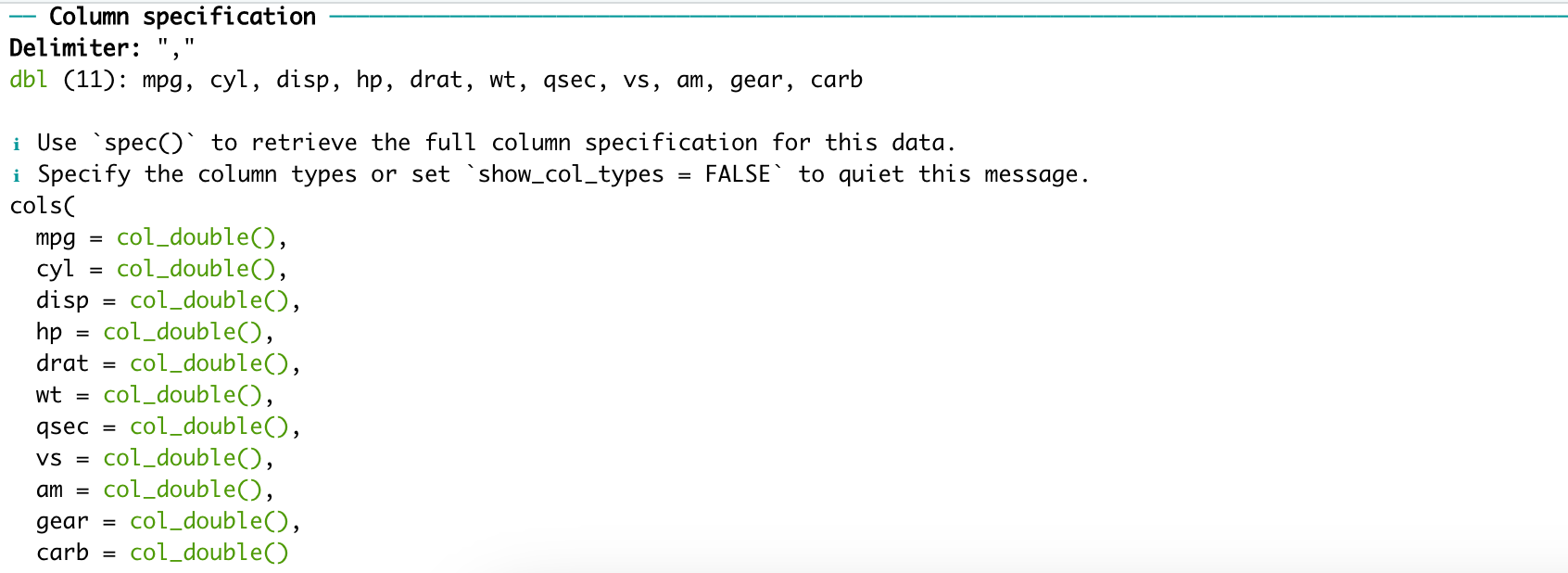
It shows the column specification of the tibble.
What Flm wrote. And I'd add it's useful because you can copy-paste it into the col_types argument of read_csv(), and then:
1/ if the data changes one day and does not match the specification anymore, you can get a helpful error (instead of doing wrong computations without noticing)
2/ once the col_types is written, you can tweak it, for example reading a column as an integer or factor, and specifying levels etc.
This col_type argument is useful, but when you have many columns it's painful to type a description of each one, spec() gives you a first version.
1 Like
This topic was automatically closed 42 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.