Normally what I would do is spread the variable column, mutate to create the new variable AB, and then gather them back together. So, using the following code:
df %>% spread(key = variable, value = amount) %>%
mutate(AB = A + B) %>%
gather(A:AB, key = variable, value = amount)
My question is: is this the best approach to creating the new variable AB? Or is there a more efficient way to calculate it directly from the original data frame, e.g. perhaps somehow using group_by()?
Not reshaping with tidyr but using the tidyverse you would calculate the summary table this way
library(dplyr, warn.conflicts = FALSE)
#> Warning: le package 'dplyr' a été compilé avec la version R 3.4.4
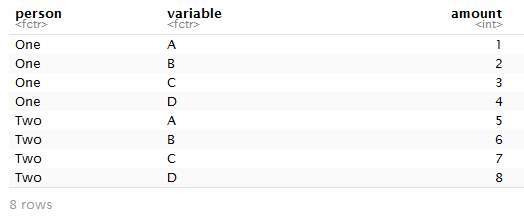
df <- data_frame(person = rep(c("One","Two"), each = 4),
variable = rep(c("A","B","C","D"), 2),
amount = 1:8)
df
#> # A tibble: 8 x 3
#> person variable amount
#> <chr> <chr> <int>
#> 1 One A 1
#> 2 One B 2
#> 3 One C 3
#> 4 One D 4
#> 5 Two A 5
#> 6 Two B 6
#> 7 Two C 7
#> 8 Two D 8
AB_df <- df %>%
filter(variable %in% c("A", "B")) %>%
mutate(variable = "AB") %>%
group_by(person, variable) %>%
summarise(amount = sum(amount))
#> Warning: le package 'bindrcpp' a été compilé avec la version R 3.4.4
AB_df
#> # A tibble: 2 x 3
#> # Groups: person [?]
#> person variable amount
#> <chr> <chr> <int>
#> 1 One AB 3
#> 2 Two AB 11
bind_rows(df, AB_df)
#> # A tibble: 10 x 3
#> person variable amount
#> <chr> <chr> <int>
#> 1 One A 1
#> 2 One B 2
#> 3 One C 3
#> 4 One D 4
#> 5 Two A 5
#> 6 Two B 6
#> 7 Two C 7
#> 8 Two D 8
#> 9 One AB 3
#> 10 Two AB 11
group_by(person): do something divided by person filter(variable %in% c("A","B")): only consider A and B summarise(sum(amount)): get the aggregate result
How is this different ? It is just another order of steps in the pipeline but it is the same lacking some (adding new AB variable and row-bind to other tab).
Your explanation is a nice addition though. thanks!
I change a little bit on my answer, ordering the filter at first.
Because I maintain the two answer in the similar data process.
(filter first is faster).
Maybe I avoid one step, so the solution is a little faster.
It would be interesting to do a performance shootout of all of these, but for my money @SteveXD’s original solution is the most elegant to read, if maybe a little opaque if you haven’t internalized what spread and gather do.
I was thinking about the conversation in this thread which touched on the idea that it’s better to take advantage of R’s column-oriented-ness than to swim upstream with rowwise operations. I’m not completely sure how well this situation connects to those ideas, but it strikes me that maybe converting the problem to a colwise operation with a minimum of steps is a major point in favor of @SteveXD’s original solution?
Totally agree ! The solution with spread and gather is the most elegant.
Spreading and gathering can be costly operation on bigger data, and when the problem hits this point, keeping a rowwise problem could become the new solution.
I nice to have the two approach in one thread : colwise and rowise!