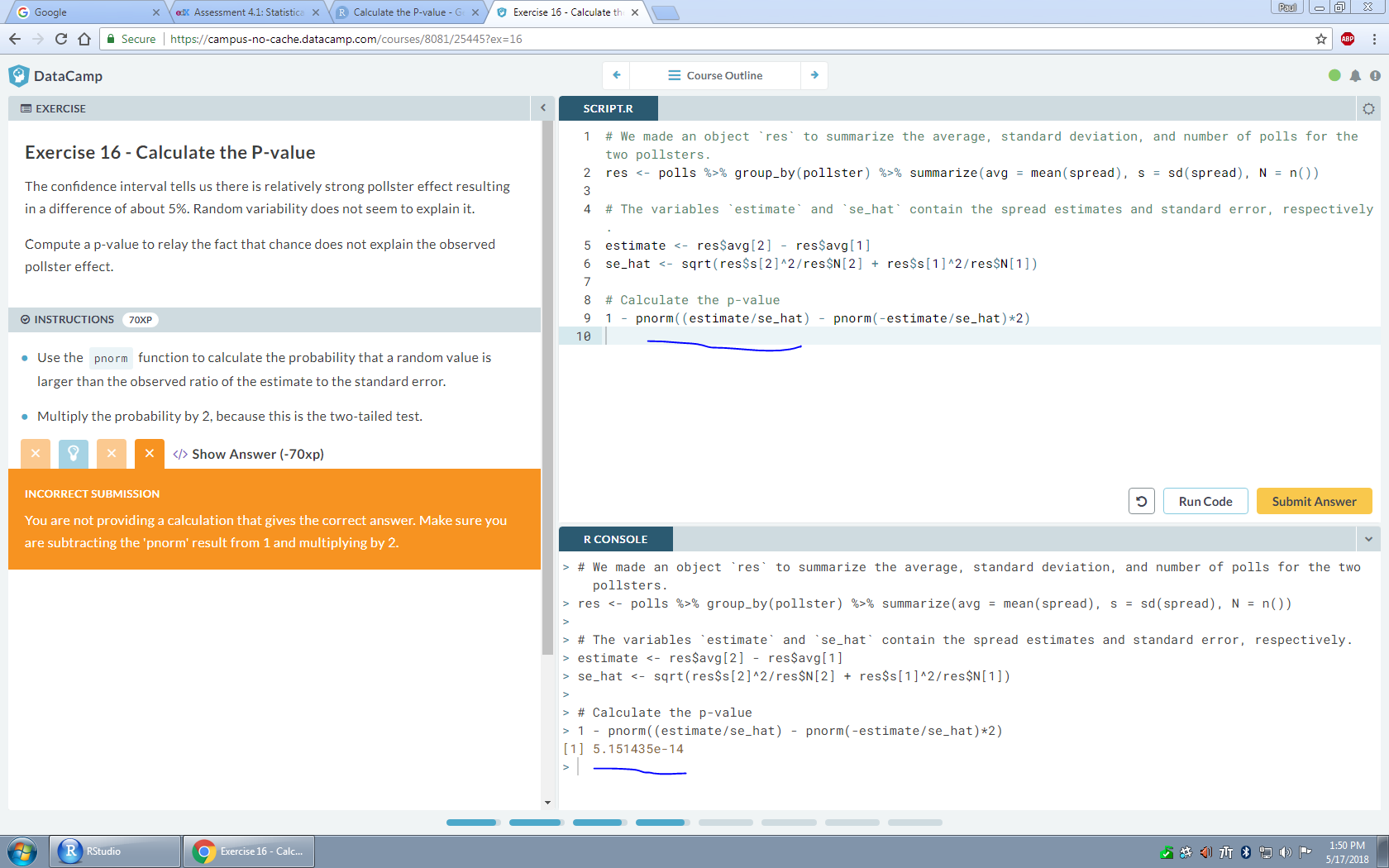
# I made an object `res` to summarize the average, standard deviation, and number of polls for the two pollsters.
res <- polls %>% group_by(pollster) %>% summarize(avg = mean(spread), s = sd(spread), N = n())
#> Error in polls %>% group_by(pollster) %>% summarize(avg = mean(spread), : could not find function "%>%"
# The variables `estimate` and `se_hat` contain the spread estimates and standard error, respectively.
estimate <- res$avg[2] - res$avg[1]
#> Error in eval(expr, envir, enclos): object 'res' not found
se_hat <- sqrt(res$s[2]^2/res$N[2] + res$s[1]^2/res$N[1])
#> Error in eval(expr, envir, enclos): object 'res' not found
# Calculate the p-value
1 - pnorm((estimate/se_hat) - pnorm(-estimate/se_hat)*2)
#> Error in pnorm((estimate/se_hat) - pnorm(-estimate/se_hat) * 2): object 'estimate' not found
What I am trying to do: Compute a p-value to relay the fact that chance does not explain the observed pollster effect.
How I am trying to calculate the p-value: Use the pnorm function to calculate the probability that a random value is larger than the observed ratio of the estimate to the standard error.
Multiply the probability by 2, because this is the two-tailed test.
subtracting the 'pnorm' result from 1 and multiplying by 2.
After the first error (the error in the first line) the values you expect are not set. So each step then reports an additional error. The first error is you need to add "library(dplyr)" to have the dplyr functions defined.
I think another error you are seeing could be a weird effect of a parentheses error in the last line (notice the two open parens in "pnorm((").
Also, all the steps you are working through are wrapped in a higher level function called t.test(). So if, after double checking help(t.test) to see if it is the test you in fact want for your application) I would suggest calling that and pulling results off the returned structure (which you can examine with str()).
1 Like
For your p-value, I might simplify to
2 * pnorm(abs(estimate / se_hat), lower.tail = FALSE)
This takes the tail area to the right of the absolute value of the test statistic and multiplies it by two to get the final p-value.
But if you can pull the p-value from an htest object (such as returned by t.test), it will be a bit simpler.
I guess the dplyr package or whichever package which is needed is already loaded as there are no errors unlike the reprex. my calculation of the p-value is incorrect.
I believe the *2 in your p-value calculation is erroneous.
Also, your parentheses are improperly nested. You are getting the normal probability for estimate/se_hat - pnorm(-estimate/se_hat)*2
The correct form should be 1 - (pnorm(estimate/se_hat) - pnorm(-estimate/se_hat)). Note, however, that this requires that estimate/se_hat be a positive value.
This is why I recommended earlier using a different approach. My suggestion is agnostic to the sign of the test statistic.
1 - (pnorm(estimate/se_hat) - (pnorm(-estimate/se_hat)))
This line passed the autograder. you were right, the *2 was not needed yet it was clearly required in the instructions.
as for the placement of the ( ) , that's an art unto itself as it could make or break the output.