I need help with a project I am working on. I created a new data from the Iris data which is similar to what I am working on.,
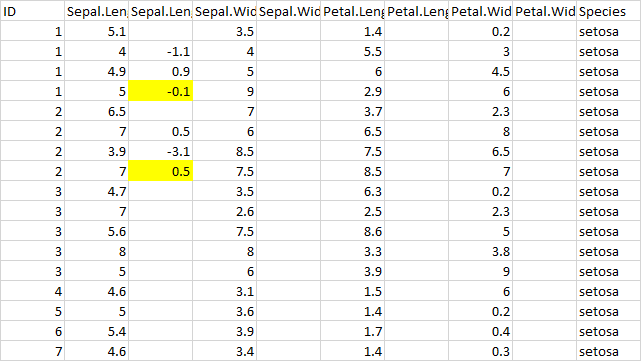
For each patient ID, I want to calculate the change that has occurred. For example, for Sepal Length Change(ie L.Change), I have the value to be (5.0-4.9-4.0-5.1=-9). I will then put this value (-9) on the last row for that patient ID number (thus 1 in this case) and then do same for the rest of the patients.
I was hoping the code below could work then I will think of how to turn it into a function, but I am getting the error below.
I am wondering if anyone can help me with a function to solve this.I have over 900 unique ID numbers(observations) and more than 30 variables.
ID Sepal.Length L.Change Sepal.Width W.Change
1 5.1 NA 3.5 NA
1 4.0 NA 4.0 NA
1 4.9 NA 5.0 NA
1 5.0 NA 9.0 NA
2 6.5 NA 7.0 NA
2 7.0 NA 6.0 NA
2 3.9 NA 8.5 NA
2 7.0 NA 7.5 NA
3 4.7 NA 3.5 NA
3 7.0 NA 2.6 NA
The problem with the line of code you posted is that L.Change does not exist outside of irisn. You have to refer to it as irisn$L.Change. Also, == compares two objects for equality, it does not assign a value to the left hand side.
I do not think that is a workable approach to get your values, though maybe someone else can see a way to do it along those lines. I suggest staying away from placing summary calculations in a special column at the end of a group of rows. That is common in spreadsheets but it does not match well with the way R works. I took the liberty of removing the two "Change" columns and summarizing the data into a new data frame using typical R functions for grouping rows and summarizing results. Does the code below help you at all? I realize I do not know what you need to do next, so this could be useless to you.
Thanks for your quick response to my question. I guess my calculation earlier on deviated from what I needed in the actual data. So what I intend to do in the actual data is to sum up the difference at each time points which in this case will be the sum of (4.0-5.1)+(4.9-4.0)+(5.0-4.9) = (-1.1)+(0.9)+(0.1)=-0.1
So with the last row, since I did not want to create a new row, what I do is to take the difference/ change that has occurred at that time and add it to the sum of the previous change values. If a new row will help us to do this, then that will be fine.
Because the focus of this analysis is on the sum of these changes for each ID, I would like to create a new column called the change(#just beside each variable). Or create this change value in excel before importing into R ( as I have done)
I will take only the ID and the new values(thus the sum of the change) for the analysis.
If you only need the new values and the IDs for the analysis, I would calculate them like this. The idea is to shift the values of each ID/Feature combination by one row in a new column and calculate the sum of the differences between the original data and the shifted data. Note that the data set I used only has the first two values of ID = 3.
I am trying to model a longitudinal data over time. Some of the variables are continues and others are categorical. Can you give me a guide on how to write the code.
Please start a new thread since this is a different question. Also, I do not have experience modeling longitudinal data but I am sure other people on the forum can help you. If you prepare a Reproducible Example it will be much easier for others to help you.
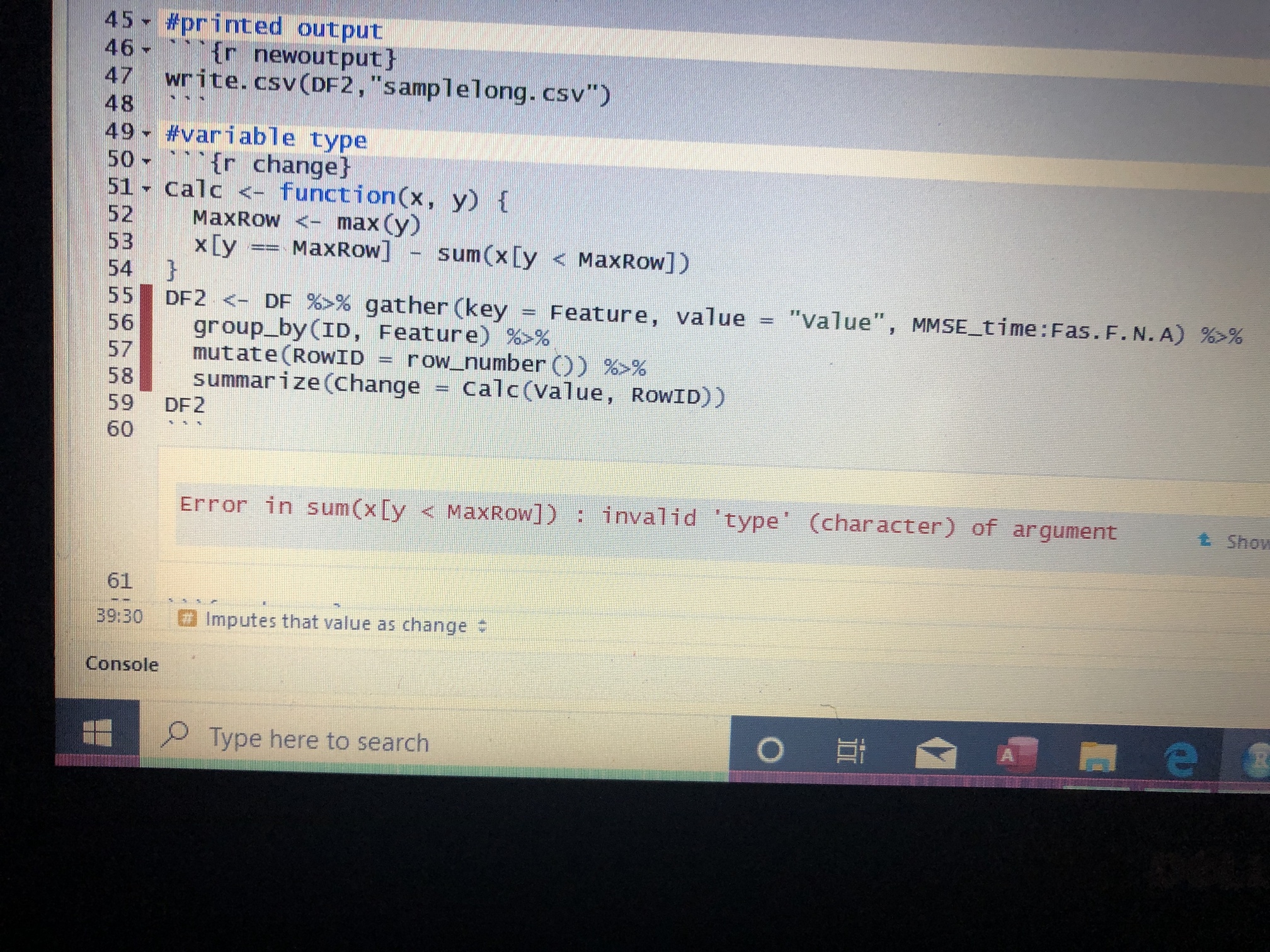
I was using the first code you helped me with on a larger data set of about 3000 rows and more than 100 columns and I had this result. I have NA’s at each column too but I am not sure if that’s the reason I am getting this.