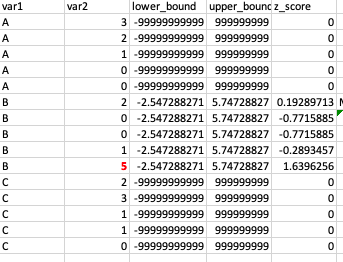
I am trying to calculate the mean, standard deviation and z score to calculate the outlier.
I need to remove outlier if my var2 is greater than or equal to 4.
To help us help you, could you please prepare a reproducible example (reprex) illustrating your issue?
In your case clean_df
Please have a look at this guide, to see how to create one:
Short Version
You can share your data in a forum friendly way by passing the data to share to the dput() function.
If your data is too large you can use standard methods to reduce it before sending to dput().
When you come to share the dput() text that represents your data, please be sure to format your post with triple backticks on the line before your code begins to format it appropriately.