Blog Explorer
Authors: Stefan Schliebs
Working with Shiny more than 1 year
Abstract: A Shiny app to browse the results of a topic model trained on 30,000+ blog articles about the statistical programming language R
Shiny app: https://nz-stefan.shinyapps.io/blog-explorer/
Full Description:
Analysing 10+ Years of R Blogs
An article by Julia Silge about Structural Topic Models gave the inspiration for this project. I have often struggled to extract meaningful information from free text documents but Julia's results looked very convincing. Additionally the chosen topic model algorithm can take advantage of additional meta information associated for each document. The blog article by Andrea De Angelis explained how to exploit publication dates of documents and show topic trends over time. After some digging I found the vignette of the stminsights package which provides functionality to extract topic correlation graphs from the trained structural topic model. All these resources put enough ideas in my head to create this app.
Data
I am a fond reader of blog articles published on R-Bloggers. It is an aggregator for blogs about R and has been around for more than a decade. I thought it would be very interesting to see how the R scene has developed over the last 10 years. What topics were talked about in the past, what are people writing about today? Would we see the rise of Shiny, the tidyverse, Rmarkdown, CRAN releases, conference announcements?
I scraped the blog data from R-Bloggers from their public archives using the super convenient rvest package. The process is split into three phases to allow me later to change my mind about the particular processing of articles.
- Obtain a list of links to articles published on R-Bloggers
- Download each article from the link collection
- Parse each document and combined them into a single dataframe
For each document I also collected meta information such as blog title, publication date, author and URLs to the original blog. In total I collected more than 30,000 articles published as early as Jan 2010.
For the ongoing data refresh I download the R-Blogger RSS feeds every day using a script running in a Docker container on AWS on a daily schedule. The RSS feed is a XML file that contains the latest 25 articles published on the website. At the end of each month a second script in a second container combines the articles in all collected feeds with the 30,000 scraped articles and refreshes the topic model behind this application. So every month something new should appear in this Shiny app.
Topic Model
I followed Julia Silge's methodology to determine the optimal number of topics. The process involves training several models with varying number of topics and then inferring a reasonable topic number from a variety of diagnostic plots. The training took many hours to complete, I let the machine run over night despite parallelising the computation.
The topic models are generated using the stm package. Papers on the topic algorithm can be found here. Some code from the tidystm package was used to transform STM outputs into tidy format.
Did it work?
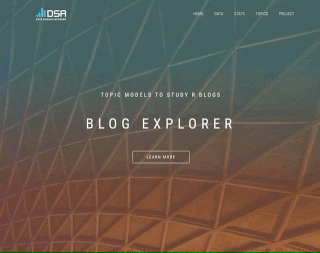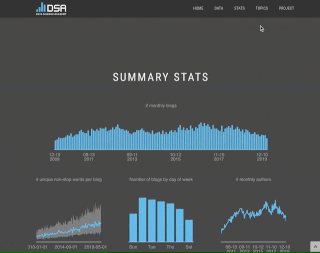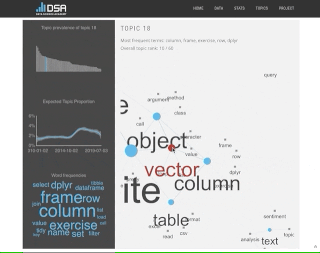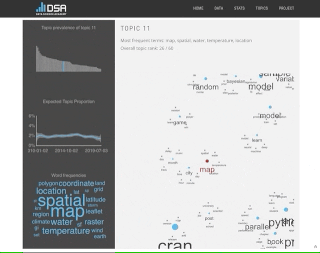
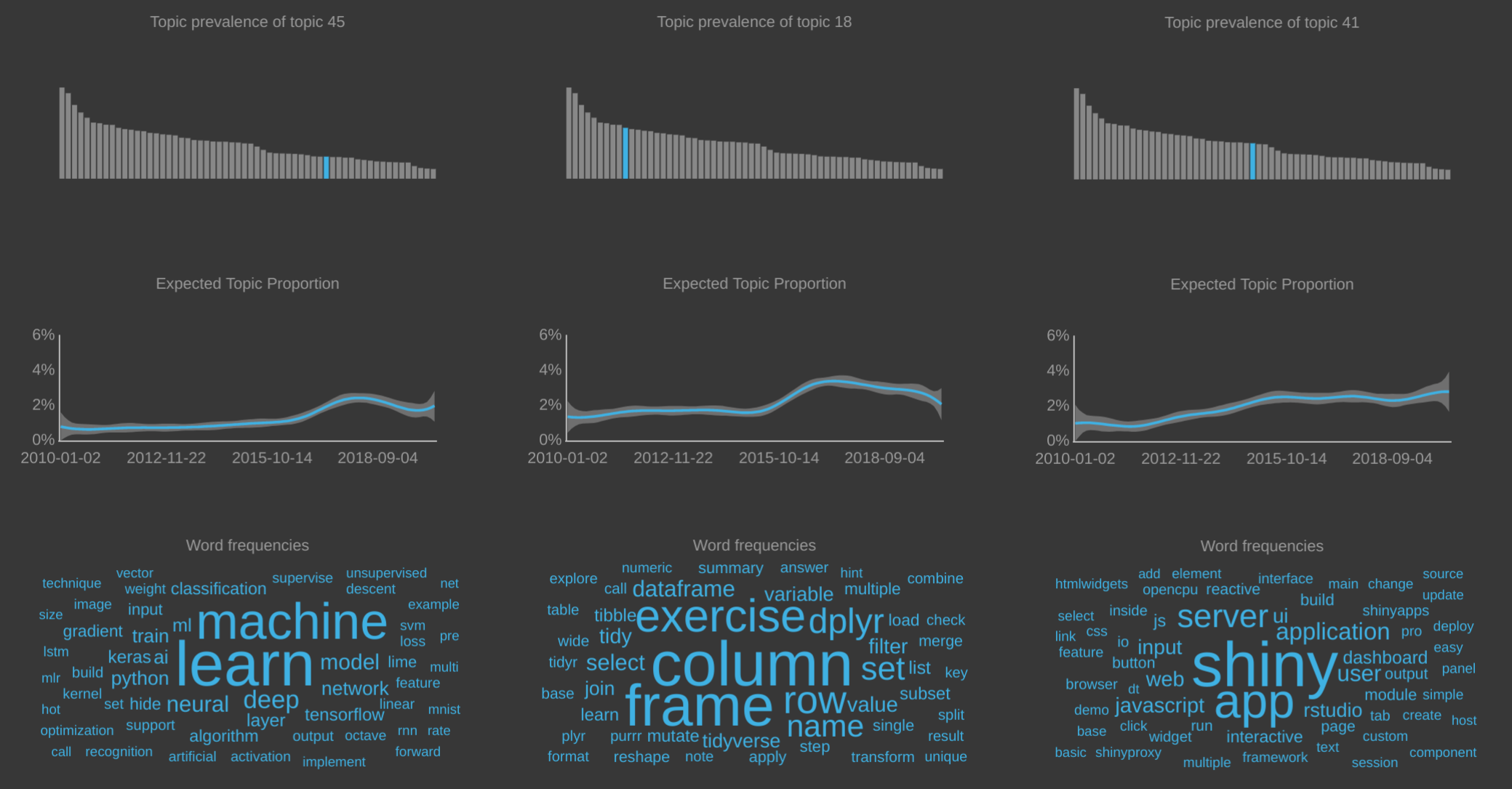
So did it actually work? Did the topic model identify relevant R trends? I think it did! Here are the results for three particular topics. The top row of bar charts shows the overall prevalence of the shown topics. The middle row shows the estimated topic proportion across the corpus over time and the bottom row of word clouds presents the top terms in each of the topics. We see the increased interest in machine learning and deep neural networks, the rise of the tidyverse (lots of dplyr verbs) and the popularity of Shiny. Click on the image to enlarge.
The topic correlation graph reveals an interesting cluster of correlated topics about specific machine learning aspects. There are two separate "modelling" topics, one about statistical models (linear/logistic regression, GLM, GAM, ANOVA) and the other about machine learning algorithms (decision trees, random forest, GBM, xgboost, train/test, validation). Related topics are about Bayesian inference (STAN, prior and posterior, MCMC), model scoring (measures, results, rules), cluster analysis (hierarchical clustering, PCA, dimensionality reduction), exploratory analysis (densities, distributions, outliers, medians and means), deep learning (neural networks, keras, tensorflow) and hypothesis testing (although this topic also contains several cricket terms which could indicate the content is about a different kind of test). Pretty good for an unsupervised algorithm!

Other big topics cover various types of visualisations (ggplot, maps), networks, time series forecasting, text mining, books and chapters, parallel processing, learning about Python, projects and tools and software, github, file formats, conference talks and presentations, APIs and Rmarkdown. There is even a topic about the US presidential election with spiking coverage in 2016 and 2012 (when the elections occurred).
Overall, I am very happy with these results. In fact, I think they are quite astonishing. Without any additional information about this corpus, the topic model has identified a lot of meaningful topics and most topics are immediately recognizable as relevant R related content.
Application
I like beautiful data products and so I used HTML templates to create a unique look for this Shiny application. The template is called Titan and is freely available. There was a bit more JavaScript foo necessary for the network visualisation.
To improve readability, the code is structured using Shiny modules.
Deployment
The development environment of this project is a Rocker based Docker container running the Open Source version of RStudio Server. Docker allows to control all aspects of the development environment, i.e. operating system, system packages and R version. The versions of R packages are tracked using the renv package. The containerisation intends to simplify the setup of a working development environment.
Category: Technology
Keywords: NLP, topic modelling, HTML themes
Shiny app: https://nz-stefan.shinyapps.io/blog-explorer/
Repo: GitHub - nz-stefan/blog-explorer: Analysing 10+ Years of R Blogs
RStudio Cloud: Posit Cloud
Thumbnail:
Full image: