I routinely collect small data sets where what I'm interested in is measured by two proxy measurements which a generally (although usually not perfectly) correlated. Usually there is a treatment and control across 2-4 conditions. Traditionally people collecting this sort of data plot bar charts similar to this:
library(tidyverse)
# Data
set.seed(123)
df <- data_frame(condition = sort(rep(LETTERS[1:4], 40)),
treatment = rep(c(rep("teatment", 20),
rep("control", 20)), 4),
meas1 = c(rnorm(20, 15, 1),
rnorm(20, 20, 1),
rnorm(20, 45, 2),
rnorm(20, 50, 2),
rnorm(20, 30, 1),
rnorm(20, 40, 1),
rnorm(20, 70, 3),
rnorm(20, 85, 3)),
meas2 = c(rnorm(20, 10, 1),
rnorm(20, 18, 1),
rnorm(20, 40, 2),
rnorm(20, 45, 2),
rnorm(20, 25, 1),
rnorm(20, 35, 1),
rnorm(20, 70, 3),
rnorm(20, 85, 3)))
# Calculate margin of error
moe <- function(data, alpha = 0.05){
moe <- qt(1 - (alpha / 2), sum(!is.na(data)) - 1) * (sd(data, na.rm = TRUE)/sqrt(sum(!is.na(data))))
return(moe)
}
# Traditional graph
df %>%
gather(meas, value, -condition, -treatment) %>%
group_by(condition, treatment, meas) %>%
summarise(m = mean(value), moe = moe(value)) %>%
ggplot(aes(treatment, m, fill = condition)) +
geom_col(position = position_dodge()) +
geom_errorbar(aes(ymin = m - moe,
ymax= m + moe),
position = position_dodge()) +
facet_grid(.~meas)
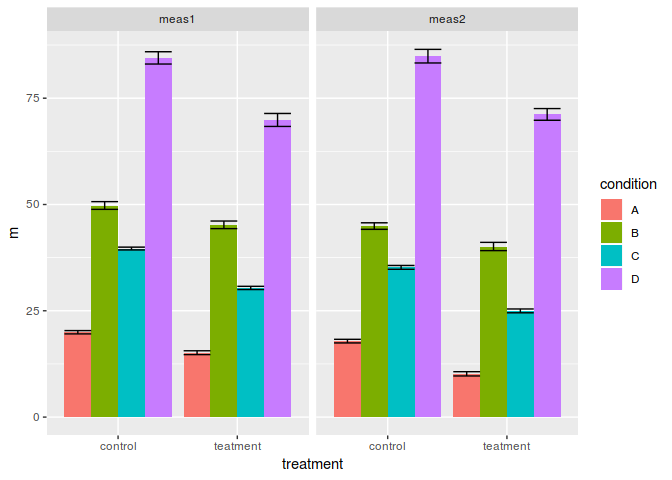
however I don't think this is optimal as:
- The two plots are attempting to say the same thing but observations about the same individual are split into two so you constantly have to ask yourself; does proxy measurement 1 suggest the same conclusion as proxy measurement 2?
- Bar charts obscure variation in data
- Comparing between different bars even on the same graph is difficult if they are non-adjacent.
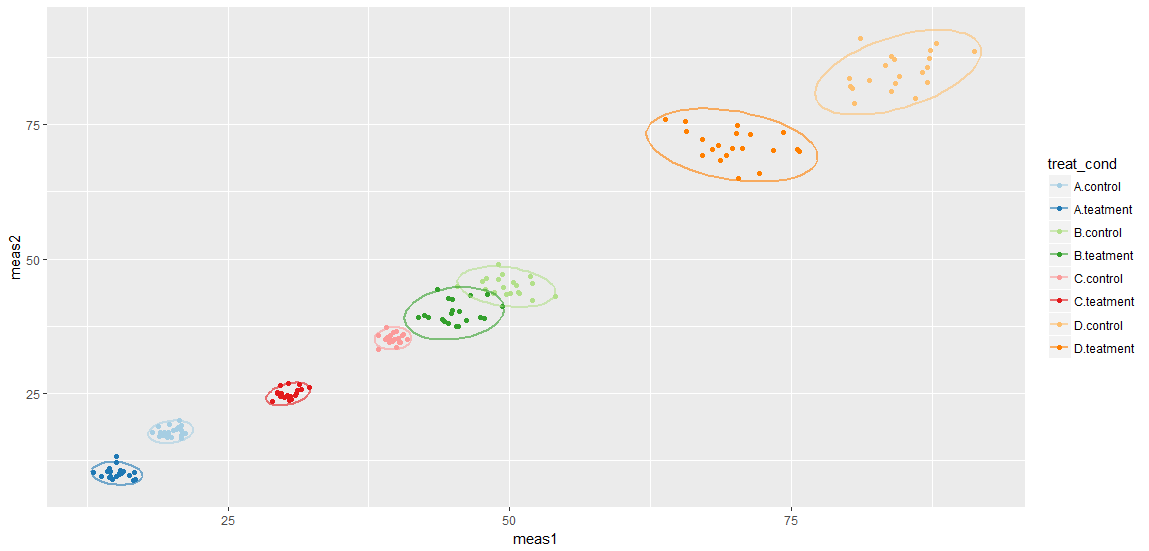
Given the small size of the data I feel that the data is better served by simply plotting the points in a scatter plot and faceting by condition. Maybe a confidence ellipse.
# Improved ?? Maybe??
ggplot(df, aes(meas1, meas2, colour = treatment)) +
geom_jitter() +
stat_ellipse(size = 1, alpha = 0.6) +
facet_wrap(.~condition, nrow = 2, scales = "free")
I like this as:
- Both proxies are presented together on the same chart and condition seems like a natural division.
- Variation between individuals is presented
- At a glance it is easy to see qualitatively if and how the treatment and control differ you simple need to ask yourself whether the point clouds overlap
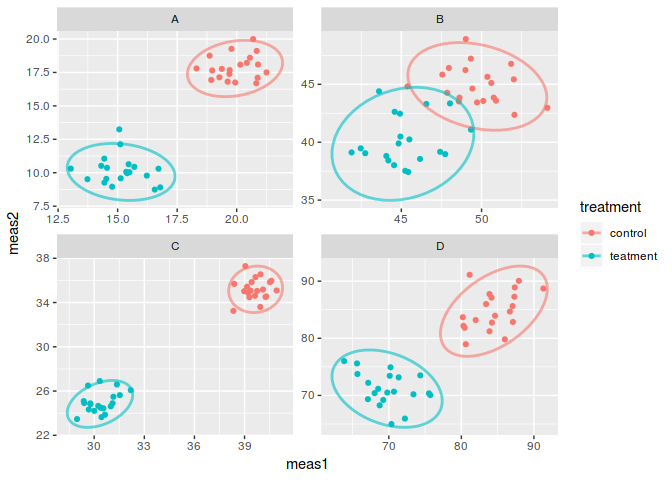
I think this is a really good solution however I am worried that comparisons between conditions could be misleading as the scales are different. If I account for this the clouds can become very small and condensed.
# Improved but small
ggplot(df, aes(meas1, meas2, colour = treatment)) +
geom_jitter() +
stat_ellipse(size = 1, alpha = 0.6) +
facet_wrap(.~condition, nrow = 2)

Here comparing between conditions is possible as the scales are the same and I think the graph facilitates accurate interpretations of the data so it isn't terrible. Nevertheless it is not as attractive and it does not seem to be an efficient use of space.
I would like to know whether other people agree with my thoughts on this and whether anyone has a better solution which uses space more efficiently.
Created on 2018-07-12 by the reprex package (v0.2.0).