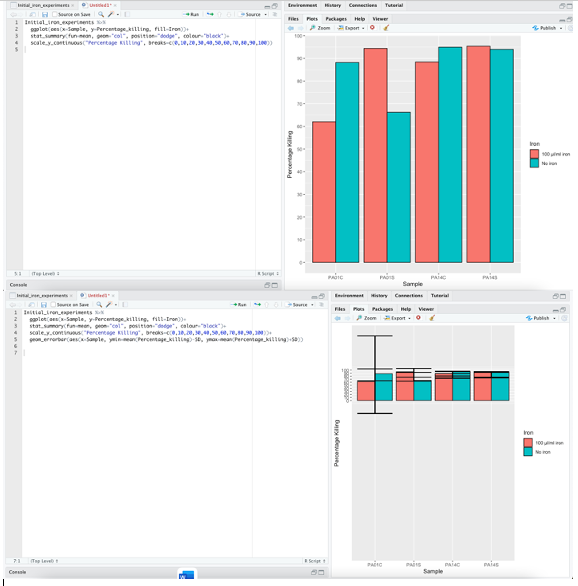
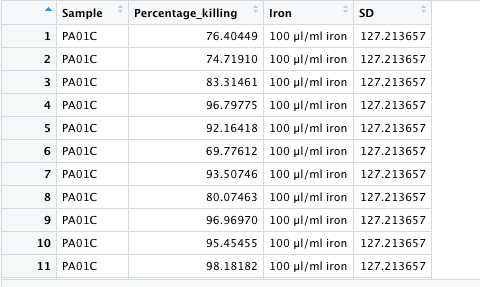
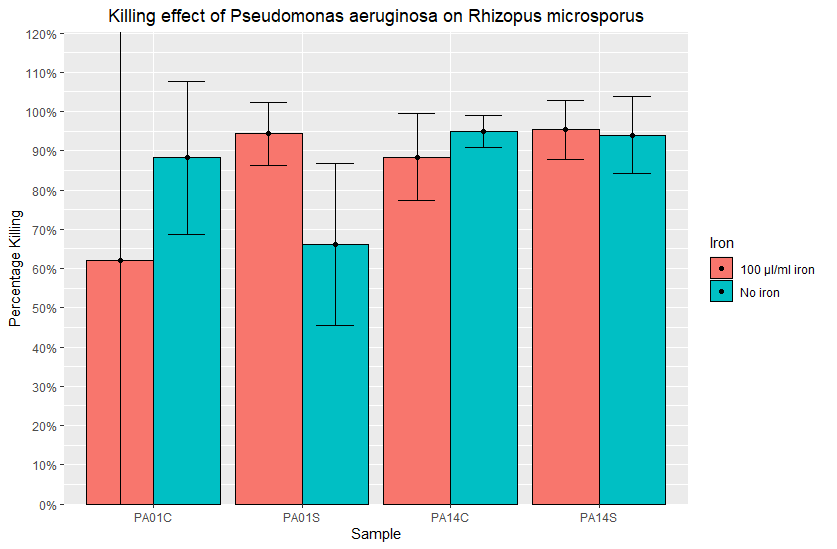
This is my data (sorry there's quite a bit, but I'm sure it's better if I provide it all).
> dput(Initial_iron_experiments)
structure(list(Sample = c("PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C", "PA01C",
"PA01C", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S",
"PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S",
"PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S",
"PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S", "PA01S",
"PA01S", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C",
"PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C",
"PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C",
"PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C",
"PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C",
"PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14C", "PA14S",
"PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S",
"PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S",
"PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S", "PA14S",
"PA14S", "PA14S", "PA14S", "PA14S", "PA14S"), Percentage_killing = c(76.4044943820225,
74.7191011235955, 83.314606741573, 96.7977528089888, 92.1641791044776,
69.7761194029851, 93.5074626865672, 80.0746268656716, 96.969696969697,
95.4545454545455, 98.1818181818182, 97.8787878787879, 92.6108374384236,
-491.133004926108, 97.487684729064, 97.192118226601, 98.6547085201794,
95.9641255605381, 98.6547085201794, 96.2331838565022, 51.123595505618,
74.7191011235955, 72.5280898876404, 82.6404494382023, 97.7611940298507,
96.6417910447761, 98.3208955223881, 97.5373134328358, 93.9393939393939,
96.969696969697, 98.030303030303, 98.3333333333333, 98.5221674876847,
95.5665024630542, 21.6748768472906, 97.487684729064, 95.9641255605381,
98.6547085201794, 97.4439461883408, 99.5964125560538, 100, 100,
99.0909090909091, 99.0909090909091, 94.0886699507389, 98.5221674876847,
95.8620689655172, 98.2266009852217, 71.7488789237668, 83.8565022421525,
96.7713004484305, 95.4260089686099, 15.7303370786517, 54.4943820224719,
66.9662921348315, 72.3595505617978, 59.0909090909091, 62.1212121212121,
84.3939393939394, 86.0606060606061, 54.1871921182266, 26.1083743842365,
81.0837438423645, 80.64039408867, 79.8206278026906, 75.7847533632287,
77.8026905829596, 82.914798206278, 84.8314606741573, 62.9213483146067,
93.5955056179775, 83.4831460674157, 96.6417910447761, 75.3731343283582,
90.9328358208955, 95.8582089552239, 69.6969696969697, 81.8181818181818,
88.3333333333333, 92.5757575757576, 95.5665024630542, 97.0443349753695,
67.6354679802956, 99.1133004926108, 100, 95.9641255605381, 99.5964125560538,
97.0403587443946, 93.2584269662921, 96.6292134831461, 96.9662921348315,
96.2921348314607, 94.4029850746269, 80.9701492537313, 96.0820895522388,
96.0820895522388, 90.9090909090909, 100, 94.3939393939394, 99.2424242424242,
92.6108374384236, 95.5665024630542, 97.487684729064, 98.2266009852217,
97.3094170403587, 93.2735426008969, 98.1165919282511, 90.8520179372197,
100, 100, 100, 100, 74.8768472906404, 89.6551724137931, 89.064039408867,
90.9852216748769, 100, 100, 100, 100, 89.8876404494382, 92.4157303370787,
91.2359550561798, 98.4848484848485, 100, 100, 100, 63.0541871921182,
97.0443349753695, 80.1970443349754, 97.7832512315271, 100, 100,
100, 100), Iron = c("100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron",
"100 µl/ml iron", "100 µl/ml iron", "100 µl/ml iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron", "No iron", "No iron", "No iron", "No iron",
"No iron", "No iron"), SD = c(127.213656720742, 127.213656720742,
127.213656720742, 127.213656720742, 127.213656720742, 127.213656720742,
127.213656720742, 127.213656720742, 127.213656720742, 127.213656720742,
127.213656720742, 127.213656720742, 127.213656720742, 127.213656720742,
127.213656720742, 127.213656720742, 127.213656720742, 127.213656720742,
127.213656720742, 127.213656720742, 19.4318548191016, 19.4318548191016,
19.4318548191016, 19.4318548191016, 19.4318548191016, 19.4318548191016,
19.4318548191016, 19.4318548191016, 19.4318548191016, 19.4318548191016,
19.4318548191016, 19.4318548191016, 19.4318548191016, 19.4318548191016,
19.4318548191016, 19.4318548191016, 19.4318548191016, 19.4318548191016,
19.4318548191016, 19.4318548191016, 8.01827204126994, 8.01827204126994,
8.01827204126994, 8.01827204126994, 8.01827204126994, 8.01827204126994,
8.01827204126994, 8.01827204126994, 8.01827204126994, 8.01827204126994,
8.01827204126994, 8.01827204126994, 20.6372786443555, 20.6372786443555,
20.6372786443555, 20.6372786443555, 20.6372786443555, 20.6372786443555,
20.6372786443555, 20.6372786443555, 20.6372786443555, 20.6372786443555,
20.6372786443555, 20.6372786443555, 20.6372786443555, 20.6372786443555,
20.6372786443555, 20.6372786443555, 11.1514836638692, 11.1514836638692,
11.1514836638692, 11.1514836638692, 11.1514836638692, 11.1514836638692,
11.1514836638692, 11.1514836638692, 11.1514836638692, 11.1514836638692,
11.1514836638692, 11.1514836638692, 11.1514836638692, 11.1514836638692,
11.1514836638692, 11.1514836638692, 11.1514836638692, 11.1514836638692,
11.1514836638692, 11.1514836638692, 4.05359503648241, 4.05359503648241,
4.05359503648241, 4.05359503648241, 4.05359503648241, 4.05359503648241,
4.05359503648241, 4.05359503648241, 4.05359503648241, 4.05359503648241,
4.05359503648241, 4.05359503648241, 4.05359503648241, 4.05359503648241,
4.05359503648241, 4.05359503648241, 4.05359503648241, 4.05359503648241,
4.05359503648241, 4.05359503648241, 7.54494046194481, 7.54494046194481,
7.54494046194481, 7.54494046194481, 7.54494046194481, 7.54494046194481,
7.54494046194481, 7.54494046194481, 7.54494046194481, 7.54494046194481,
7.54494046194481, 7.54494046194481, 9.90259358423519, 9.90259358423519,
9.90259358423519, 9.90259358423519, 9.90259358423519, 9.90259358423519,
9.90259358423519, 9.90259358423519, 9.90259358423519, 9.90259358423519,
9.90259358423519, 9.90259358423519, 9.90259358423519, 9.90259358423519,
9.90259358423519)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-135L))
As you can see, I calculated the SD for each variable in excel before importing it into RStudio.
Would it be easier to try and do it how you have done here ^, or should I be able to work with the already calculated SD values?