Hello Everyone, I have this project where I am comparing ID1 and ID2. When I look into the file, there are instances where ID1 has more counts than ID2 after grouping them and vice versa.If this is the case, two things are to be done:
If ID1 is more than ID2, insert and empty cells(rows) starting from ID2 to species(This will shift the 2 in ID2 down to the next column). This will indicate that an observation in ID1 has missing values for all the other variable.
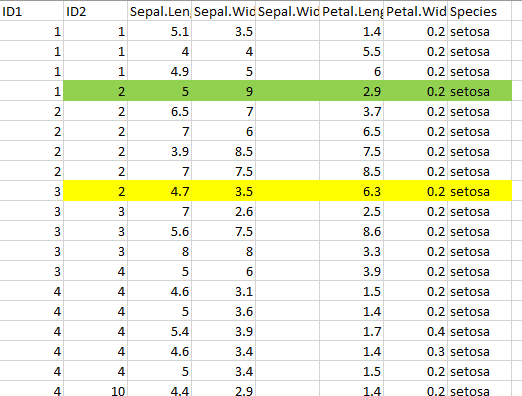
This results in

On the other hand, If ID2 has an observation to be more than ID1, we will delete the rows for that group observation. Thus, I would have deleted the portion highlighted in yellow. The part highlighted in green was shifted down to satisfy the first condition.
I have a lot of observations to look into for this and I have not been able to come up with any code to solve this. Will be grateful if anyone can help.
Thanks.