Hello,
I`m doing a rmse project, I have two vectors:
test_set: values 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5 and 5
forecast_rating: values: 2.939235 3.738641 3.419572, etc.
But I need to create a forecast_rating_2 vector, but like test_set observations, like 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5 and 5.
set.seed(1)
test_set %>%
left_join(edx1 %>%
group_by(movieId) %>%
summarise(fe = mean(rating - mu)), by = "movieId")
join <- test_set %>%
left_join(edx1 %>%
group_by(movieId) %>%
summarise(fe = mean(rating - mu)), by = "movieId")
forecast_rating <- mu + join$fe
forecast_rating
NOW RMSE:
mu <- mean(edx1$rating)
mu
set.seed(1)
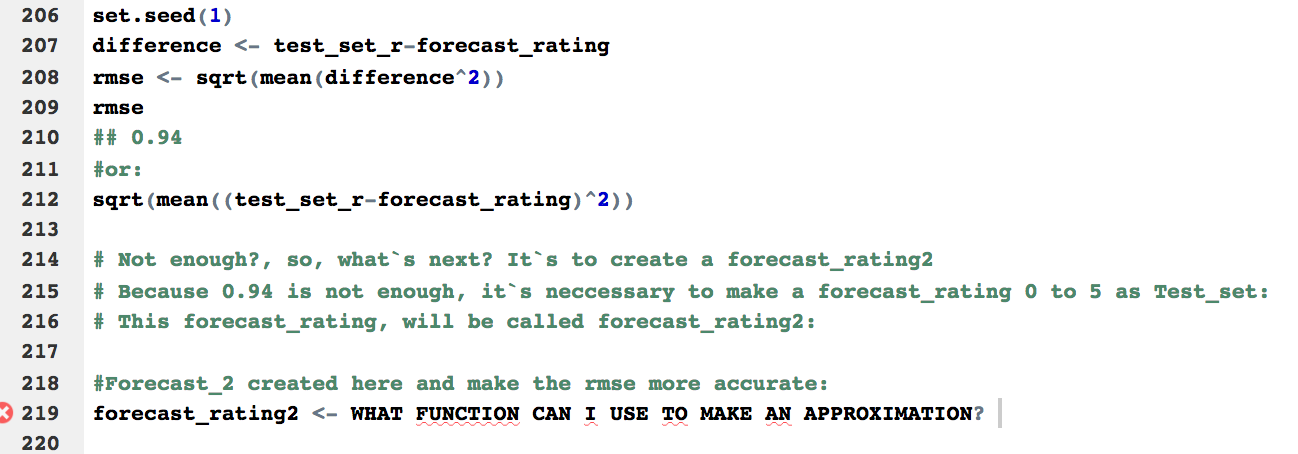
difference <- test_set_r-forecast_rating
rmse <- sqrt(mean(difference^2))
rmse
0.94
(0.94 IS NOT GOOD, BECAUSE I NEED TO HAVE LESS THAN 0.9, so I think if I have a forecast_rating_2 vector, I will be more close to a 0.8 approximations.
Thank you!


Any recommendation will be very useful
thanks a lot