Hi All,
I am having a problem with batch processing, namely I don't know how to do it outside of sprak, and as my organization doesn't have cluster set up I don't think I can use it. I certainly cannot transfer the data over.
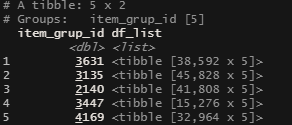
My main problem is that my script is set up for doing nested tables for a batch of the item groups (n = 20) which are pulled into R from SQL via odbc. These groups are used to select item ids in order to get the related time-series data. The format after the querey would be item_grup as the nested tables row ids and the time series data as dataframes nested in the rows for the relevant item groups.
The script then goes through a considerable amount of wrangling and calculations, which is all processed in parallel before finally creating some metrics for each item group that are then fed back into the database. While I attempt to reduce memory demand at each stage, the nested table still reaches around 6gb of ram for a nested table of just 10 item groups. So at 20 we are about at the maximum here for local processing, and I need to work through 2000 active groups.
What I need to do is apply this process/script to several thousand item groups. Which I am not sure how to do, I was thinking I could get the item groups database and add create grouping numbers for each chunk of item groups, to be processed, and then apply the script to each chunk of item groups. But this last part is what I don't have a clue on how to do, and I'm not sure how to make the script work through chunks of item groups iteratively.
I'm not used to putting things into production as most my work is experiments which developers put into practice, so I would appreciate any ideas, thanks for reading.
image below is basic structure of nested table before wrangling.