Confidence interval will be two numbers, so I don't think it's possible to store in a single column as numbers. You can store them in characters though. In the following example, I stored in the form LCB - UCB. I hope you can modify this example in your preferable format.
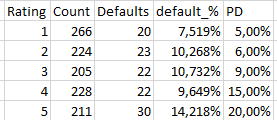
Group <- data.frame(Rating = 1:5,
Count = c(266, 224, 205, 228, 211),
Defaults = c(20, 23, 22, 22, 30),
PD = c(5, 6, 9, 15, 20))
Group$BinomTest <- apply(X = Group,
MARGIN = 1,
FUN = function(t)
{
ci <- binom.test(x = t[3],
n = t[2],
p = (t[4] / 100),
alternative = "two.sided",
conf.level = 0.90)$conf.int
paste0(round(x = ci,
digits = 4),
collapse = " - ")
})
Group
#> Rating Count Defaults PD BinomTest
#> 1 1 266 20 5 0.0504 - 0.1074
#> 2 2 224 23 6 0.0712 - 0.1423
#> 3 3 205 22 9 0.0738 - 0.1497
#> 4 4 228 22 15 0.0662 - 0.1349
#> 5 5 211 30 20 0.1042 - 0.1879
Created on 2019-05-31 by the reprex package (v0.3.0)
And, by the way, I stored them in raw limits. You can easily change them to percentages.
If using two columns is an option, then I'd like to add another option using development version of tidyr.
library(magrittr)
Group <- data.frame(Rating = 1:5,
Count = c(266, 224, 205, 228, 211),
Defaults = c(20, 23, 22, 22, 30),
PD = c(5, 6, 9, 15, 20))
Group %>%
dplyr::mutate(CI = purrr::pmap(.l = .,
.f = purrr::lift_vd(..f = function(t)
{
ci <- binom.test(x = t[3],
n = t[2],
p = (t[4] / 100),
alternative = "two.sided",
conf.level = 0.90)$conf.int
names(x = ci) <- c("LCB", "UCB")
ci
}))) %>%
tidyr::unnest_wider(CI)
#> # A tibble: 5 x 6
#> Rating Count Defaults PD LCB UCB
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 266 20 5 0.0504 0.107
#> 2 2 224 23 6 0.0712 0.142
#> 3 3 205 22 9 0.0738 0.150
#> 4 4 228 22 15 0.0662 0.135
#> 5 5 211 30 20 0.104 0.188
Here, I've used lift_vd because I don't know how to write functions with more than one step in the form ~ ..., and somehow I can't use normal functions in pmap without lift inside pmap.
Andres, can I request you to help me in this matter and improve this solution?
Edit
Here's a tidyverse solution:
library(magrittr)
Group <- data.frame(Rating = 1:5,
Count = c(266, 224, 205, 228, 211),
Defaults = c(20, 23, 22, 22, 30),
PD = c(5, 6, 9, 15, 20))
Group %>%
dplyr::mutate(temp = purrr::pmap(.l = .,
.f = purrr::lift_vd(..f = function(t)
{
with(data = binom.test(x = t[3],
n = t[2],
p = (t[4] / 100),
alternative = "two.sided",
conf.level = 0.90),
expr = list(LCB = conf.int[1],
UCB = conf.int[2],
PV = p.value))
}))) %>%
tidyr::unnest_wider(col = temp)
#> # A tibble: 5 x 7
#> Rating Count Defaults PD LCB UCB PV
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 266 20 5 0.0504 0.107 0.0663
#> 2 2 224 23 6 0.0712 0.142 0.0110
#> 3 3 205 22 9 0.0738 0.150 0.392
#> 4 4 228 22 15 0.0662 0.135 0.0254
#> 5 5 211 30 20 0.104 0.188 0.0384
As to why your code fails, you code works fine for the first run, if you change t[4] to t[4]/100. If you run again, probably you'll get the same error, because then one element of the row is character because of paste0. If you skip that (it's unnecessary), it'll work perfectly. See below:
Group <- data.frame(Rating = 1:5,
Count = c(266, 224, 205, 228, 211),
Defaults = c(20, 23, 22, 22, 30),
PD = c(5, 6, 9, 15, 20))
function_PV <- function(t)
{
binom.test(x = t[3],
n = t[2],
p = (t[4] / 100),
alternative = "two.sided",
conf.level = 0.90)$p.value
}
Group$pValue<- apply(X = Group, MARGIN = 1, FUN = function_PV)
Group
#> Rating Count Defaults PD pValue
#> 1 1 266 20 5 0.06630413
#> 2 2 224 23 6 0.01097650
#> 3 3 205 22 9 0.39154014
#> 4 4 228 22 15 0.02544170
#> 5 5 211 30 20 0.03842723