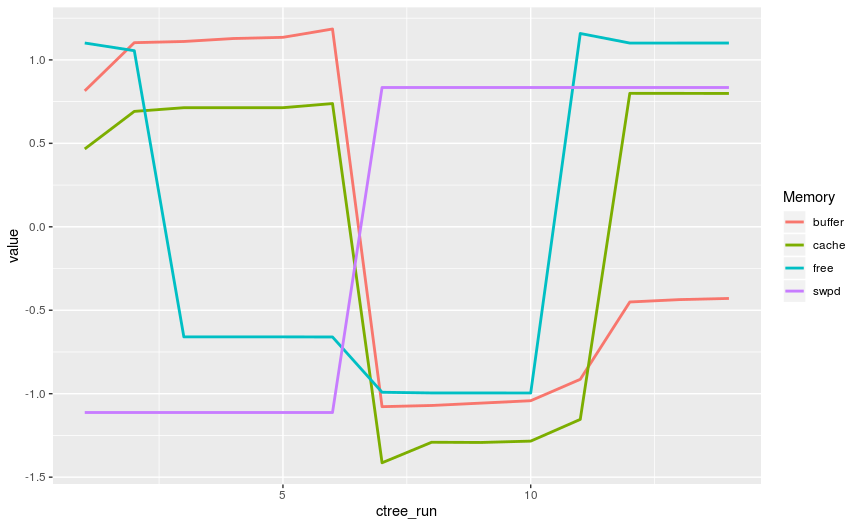
The ctree decision tree algorithm from party library crashed with 500-record training set from my personal computer. I recorded the following memory consumption with ctree algorithm while running the ctree algorithm from my personal computer:
From the graph, it is pretty sure that the ctree consumed great amount of memory. Though there are many Decision Tree algorithm's implementations available from CRAN, they all perform the similar function. Would the information regarding their performance and their resource utilization be possible available, so we can decide the right algorithm implementation to use by the nature of our tasks and resource we have, any idea?
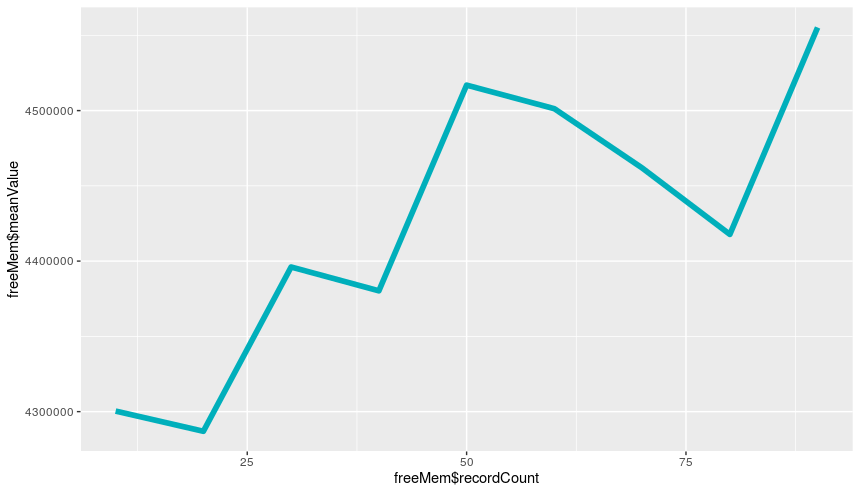
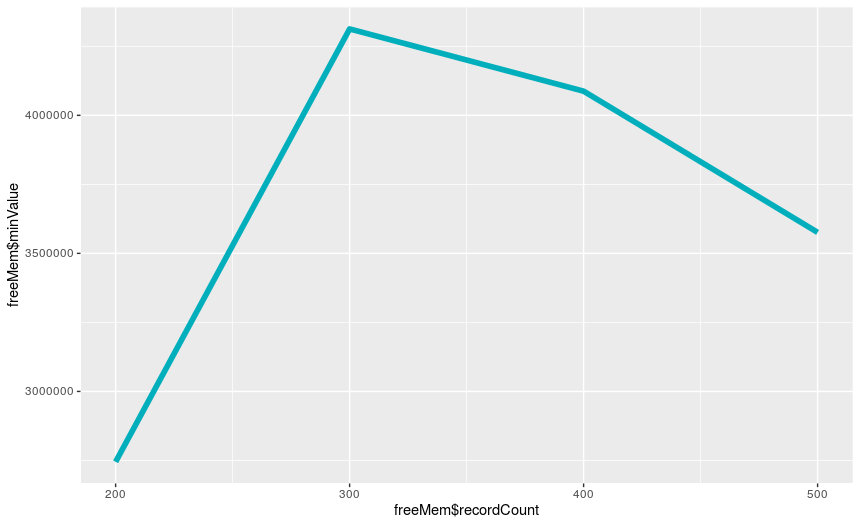
Further study the ctree algorithm, I found it seems the correlation between memory usage and record numbers do not exist for the ctree algorithm. I recorded both the minimum level of memory usage and mean level of memory usage every second during the ctree algorithm run with [ 10, 20, 30, 40, 50, 60, 70, 80, 90, 100] records and [ 200, 300, 400, 500] records. Below are the plot diagrams for memory usage: