Hello!
Is it possible to sort every single row within a data table (alphabetically)?
The first column shows different combinations of items while the second column contains the quantity of each item (which obviously shouldn't get lost in the sorting process).
My goal is to join duplicate variations in a second step.
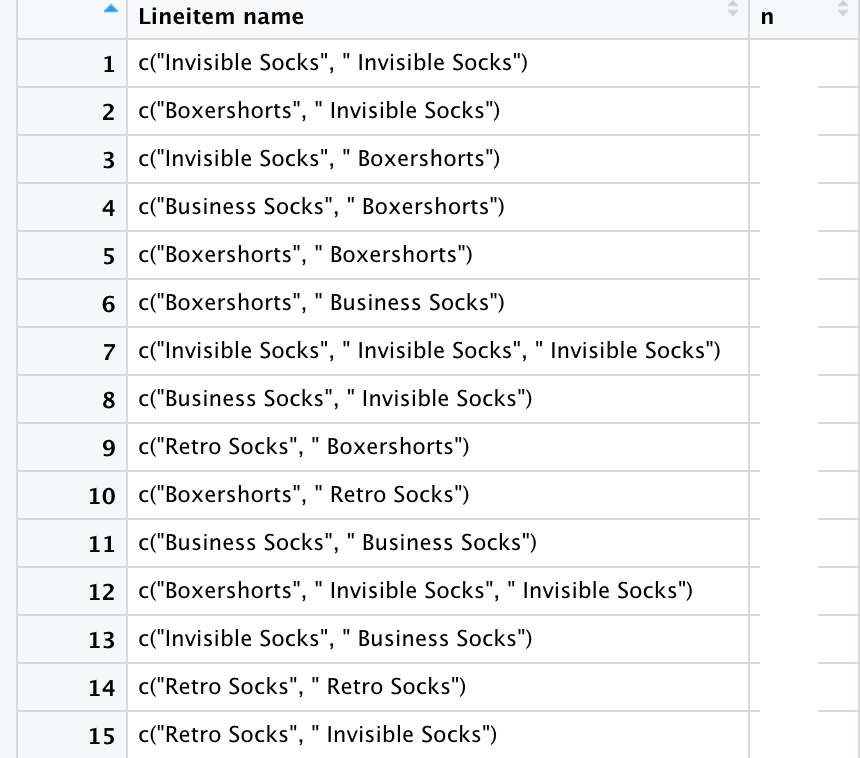
The output should look something like this (in column 1):
1: c("Invisible Socks", "Invisible Socks")
2: c("Boxershorts", "Invisible Socks")
3: c("Boxershorts", "Invisible Socks")
and so on...
I'm really looking forward to any helpful answer! ![]()

