I'm currently trying to analyse the missigness of data in about 480 xlsx-files built in a similar pattern.
For this purpose I initially imported the xlsx-files and have put them in a list.
Steps I've taken so far:
I imported all the data of interest
# Importing all relevant files
file.list <- list.files(path, pattern = '*.xlsx')
nested.list <- map(file.list, read_xlsx)
I prepared some name lists
# Name lists
colnames <- c("colname1", ..."colname13"
name_list_1 <- c("somename1", ... "somename10")
name_list_2 <- c("somename1_2", ... "somename10_2")
I prepared a function to do the adjusting work for all the files.
Here I want (among others [...]) to
- add 2 columns with names from two character lists and
- add a column with information about the NA's
adjust <- function(list) {
colnames <- c("colname1", ..."colname13"
name_list_1 <- c("somename1", ... "somename10")
name_list_2 <- c("somename1_2", ... "somename10_2")
for (i in seq_along(list)) {
result <- list[[i]] %>%
[...]
setNames(colnames) %>%
slice(1:444) %>%
mutate_at(c(4:13), as.numeric) %>%
mutate(name1 = map(list[[i], name_list_1),
name2 = map(list[[i], name_list_2),
missing = pmap(list[[i]], ~rowSums(is.na(.))
return(result)
}
}
I applied the function on the nested list
nested.list <- map(nested.list, adjust)
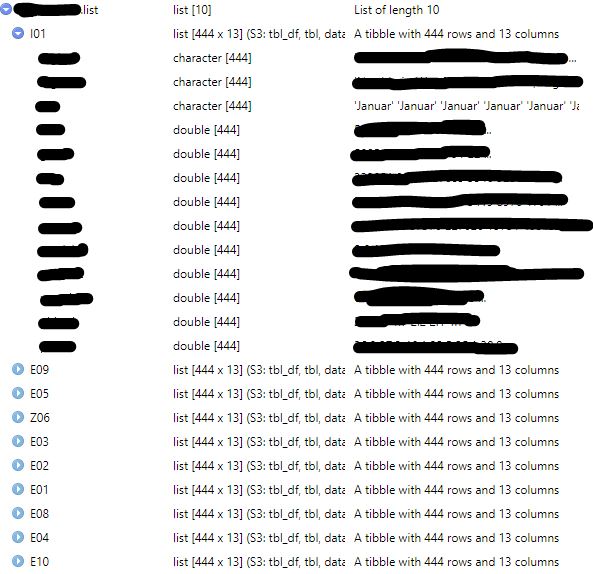
Ideally, I would have an output which, for every line and list, contains information about the number of missing values and two columns with thame names in the lists name_list_1 and name_list_2 - which I don't get up to here.
When I remove the following snippet from the function code
mutate(name1 = map(list[[i], name_list_1),
name2 = map(list[[i], name_list_2),
missing = pmap(region_m01.list[[i]], ~rowSums(is.na(.))
I get the result in the attached picture, with the desired adjustments defined in the remaining code.
[Edit 2020-06-30T19:14:00Z ]: I'm in shock right now ![]() : every line of code inside my function seems to be copying the values of the first list into all the other 9 lists! Can someone tell me why this is happening? ]
: every line of code inside my function seems to be copying the values of the first list into all the other 9 lists! Can someone tell me why this is happening? ]
For some reason I'm not able to add the before mentioned columns name1, name2, and missing.
I tried to find some workaround by indexing, using append(), cbind() , map() with ~something. etc. but none of it worked and after all I'd really like to find a neat and "tidy" solution to this.
Can anybody help?