Dear all,
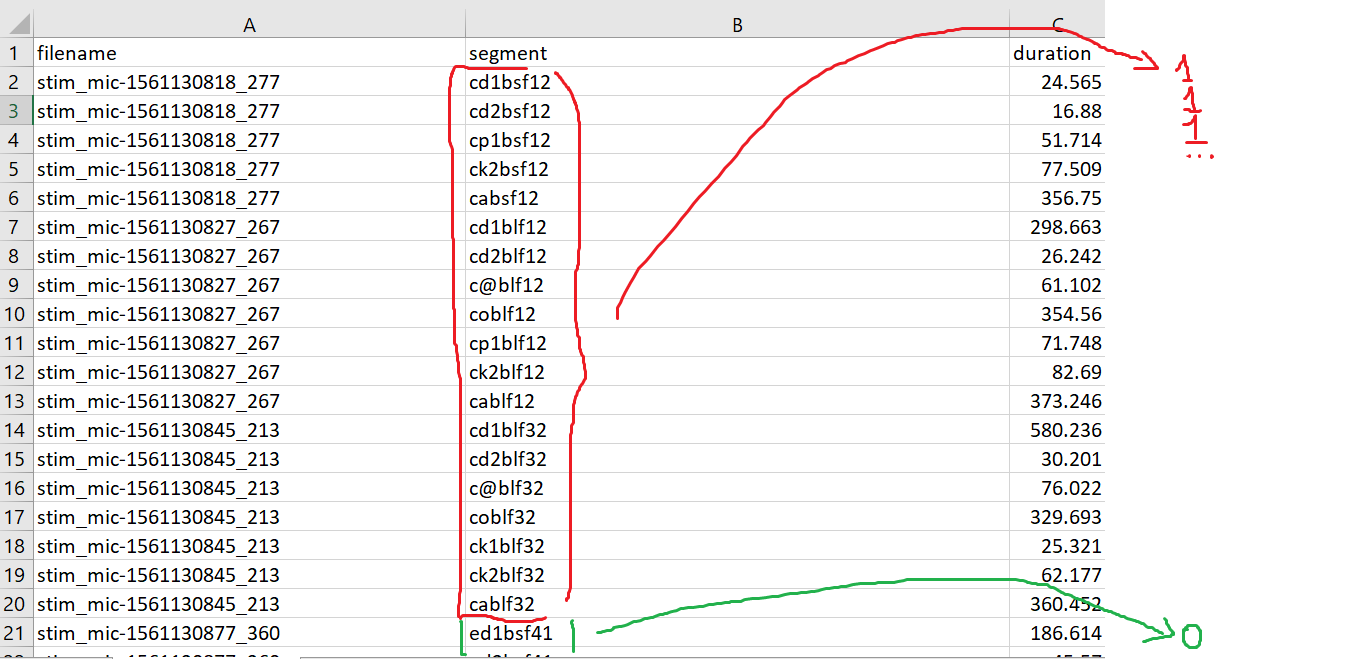
The screenshot displays a spreadsheet with three variables.
I wish to add a fourth variable called "presence" filled with observations related to the column "segment".
For each of the observations in "segment" that start with the letter "c", the character "1" would be written in "presence".
On the other hand, "0" would be added for each observation in "segment" that starts with the letter "e".
As I am new to RStudio, I would appreciate your help to understand how to approach this task.
Thank you,
Best,
dplyr::case_when would be a good choice for this. The way to use this is like so:
data %>%
mutate(
newvar = case_when(
x == y ~ 'result1',
x != y ~ 'result2'
)
)
If you are able to provide a reprex of your data , we can help you dig into extracting the e and c characters.
1 Like
Dear Derek,
Thank you very much.
I would really appreciate receiving more help.
This is the first time I tried to do a reprex.
Is the reprex below right?
I hope I got it right. If not, I am sorry. I am learning about this new thing.
Best,
setwd("~/exps_analyses/2022_exp_analyses/2022_7_durations_js_analyses/js_fr")
data <- read.csv("duration_js_tier_4.csv", header = T)
head(data)
#> ï..filename segment duration
#> 1 stim_mic-1561130818_277 cd1bsf12 24.565
#> 2 stim_mic-1561130818_277 cd2bsf12 16.880
#> 3 stim_mic-1561130818_277 cp1bsf12 51.714
#> 4 stim_mic-1561130818_277 ck2bsf12 77.509
#> 5 stim_mic-1561130818_277 cabsf12 356.750
#> 6 stim_mic-1561130827_267 cd1blf12 298.663
Created on 2022-07-09 by the reprex package (v2.0.1)
Hello this is not quite a reprex as we can't reproduce your dataset based on reading a csv file that we don't have access too.
You can run dput(df) on your data frame to get code to reproduce your dataset.
As for extracting the c and e letters, substr() along with case_when can help you do that:
df<- structure(list(segment= c("event1a", "cevent2a", "cevent1a", "event1b")),row.names = c(NA, 4L), class = "data.frame")
library(dplyr)
df %>%
mutate(
newvar = case_when(
substr(segment,1,1) == 'e' ~ 0, #first letter from index 1
substr(segment,1,1) == 'c' ~ 1, #first letter from index 1
TRUE ~ -1
)
)
1 Like
Dear Darshan,
Thank you so much for taking the time to reply to my post.
I am sorry that my reprex was not correct.
I watched a video about dput(), I hope this time I got it right. Here is the result:
structure(list(ï..filename = c("stim_mic-1561130818_277", "stim_mic-1561130818_277",
In the meantime, I am practicing the solution that you suggested.
Thank you.
I want to round up the solution in the form of a proper reproducible example using the sample data (in a proper format) you have provided and adding an alternative solution to detect the starting letter. Please pay close attention to the way I'm posting the example, this would be a propper reprex for your question.
# Library calls for the used packages
library(dplyr)
library(stringr)
# Sample data in a copy/paste friendly format
sample_data <- structure(list(
ï..filename = c(
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277"),
segment = c("cd1bsf12", "cd2bsf12", "cp1bsf12", "ck2bsf12",
"cabsf12"),
duration = c(24.565, 16.88, 51.714, 77.509, 356.75)
), row.names = c(NA, 5L), class = "data.frame")
# Relevant code
sample_data %>%
mutate(presence = case_when(
str_detect(segment, "^c") ~ 1,
str_detect(segment, "^e") ~ 0
))
#> ï..filename segment duration presence
#> 1 stim_mic-1561130818_277 cd1bsf12 24.565 1
#> 2 stim_mic-1561130818_277 cd2bsf12 16.880 1
#> 3 stim_mic-1561130818_277 cp1bsf12 51.714 1
#> 4 stim_mic-1561130818_277 ck2bsf12 77.509 1
#> 5 stim_mic-1561130818_277 cabsf12 356.750 1
Created on 2022-07-09 by the reprex package (v2.0.1)
1 Like
Dear all,
Thank you for your generous help. I am learning a lot here.
I accepted Andrés' reply as a solution, but this was indeed a collective effort and I am grateful to Derek and Darshan for their contribution.
# Reproducing Andrés' solution
# Libraries
library(dplyr)
library(stringr)
# Sample data
sample_data <- structure(list(
ï..filename = c(
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277",
"stim_mic-1561130818_277"),
segment = c("cd1bsf12", "cd2bsf12", "cp1bsf12", "ck2bsf12",
"cabsf12"),
duration = c(24.565, 16.88, 51.714, 77.509, 356.75)
), row.names = c(NA, 5L), class = "data.frame")
# Relevant code
sample_data %>%
mutate(presence = case_when(
str_detect(segment, "^c") ~ 1,
str_detect(segment, "^e") ~ 0
))
#> ï..filename segment duration presence
#> 1 stim_mic-1561130818_277 cd1bsf12 24.565 1
#> 2 stim_mic-1561130818_277 cd2bsf12 16.880 1
#> 3 stim_mic-1561130818_277 cp1bsf12 51.714 1
#> 4 stim_mic-1561130818_277 ck2bsf12 77.509 1
#> 5 stim_mic-1561130818_277 cabsf12 356.750 1
system
July 17, 2022, 10:19am
8
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.