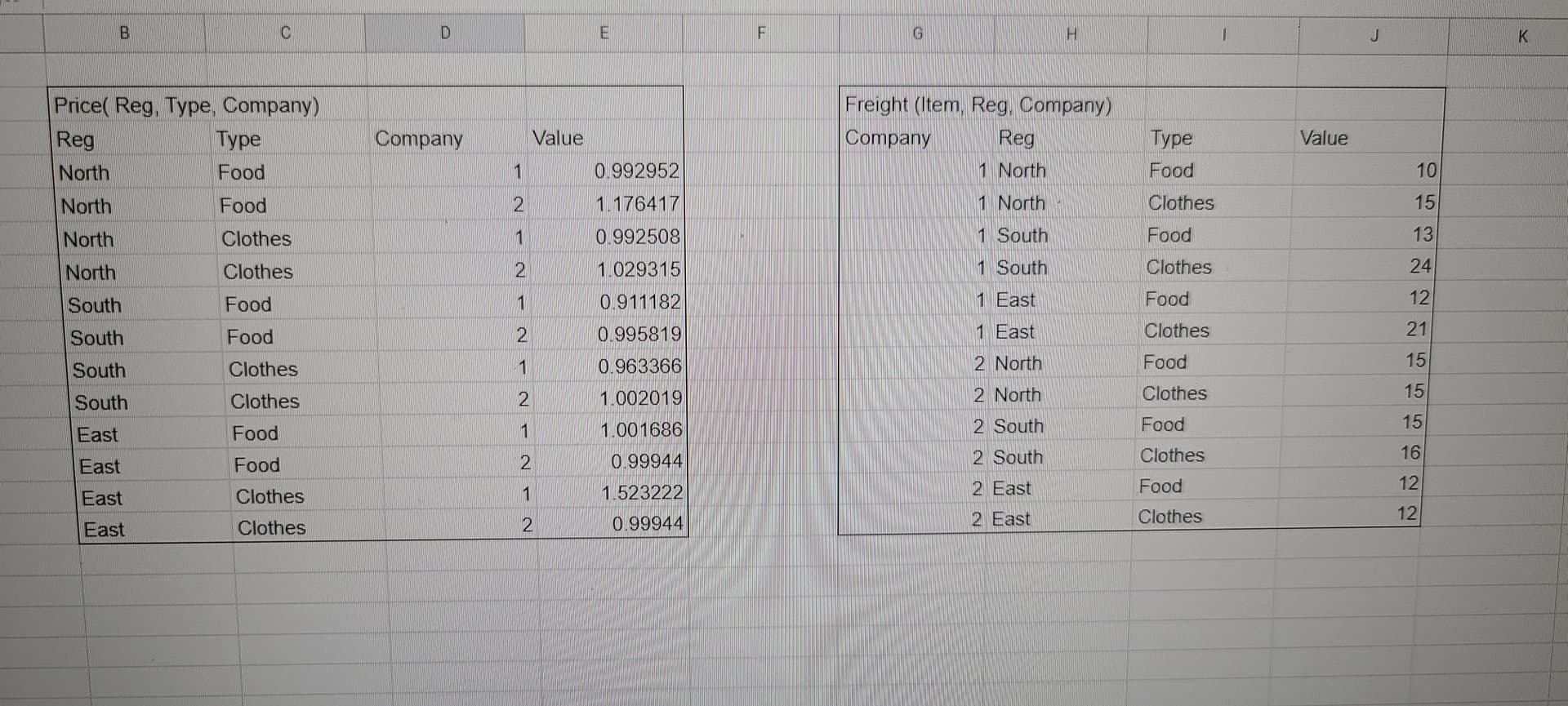
One approach would be to combine these data sets using a join. In the example below, each .csv file is read in and the Value columns are renamed to Price and Freight, respectively (I then give sample data sets of what each of these results would look like, which can be ignored in practice). Then, use a left_join() to combine the two sets. As shown, these sets combine on Reg, Type, and Company. The result is a data set with columns for Price and Freight.
library(tidyverse)
# read in .csv files and rename
price_df = read_csv('path to your price.csv') %>%
rename(Price = Value)
freight_df = read_csv('path to your freight.csv') %>%
mutate(Freight = Value)
# sample data set of what would be read in above
price_df = data.frame(
Reg = c('North', 'North', 'North', 'North', 'South', 'South'),
Type = c('Food', 'Food', 'Clothes', 'Clothes', 'Food', 'Food'),
Company = c(1, 2, 1, 2, 1, 2),
Price = c(0.992, 1.176, .992, 1.029, 0.911, 0.995)
)
# sample data set of what would be read in above
freight_df = data.frame(
Company = c(1, 1, 1, 1,
2, 2, 2, 2),
Reg = c('North', 'North', 'South', 'South',
'North', 'North', 'South', 'South'),
Type = c('Food', 'Clothes', 'Food', 'Clothes',
'Food', 'Clothes', 'Food', 'Clothes'),
Freight = c(10, 15, 13, 24,
15, 15, 15, 16)
)
# join
out = left_join(price_df, freight_df)
#> Joining, by = c("Reg", "Type", "Company")
out
#> Reg Type Company Price Freight
#> 1 North Food 1 0.992 10
#> 2 North Food 2 1.176 15
#> 3 North Clothes 1 0.992 15
#> 4 North Clothes 2 1.029 15
#> 5 South Food 1 0.911 13
#> 6 South Food 2 0.995 15
Created on 2022-10-24 with reprex v2.0.2.9000