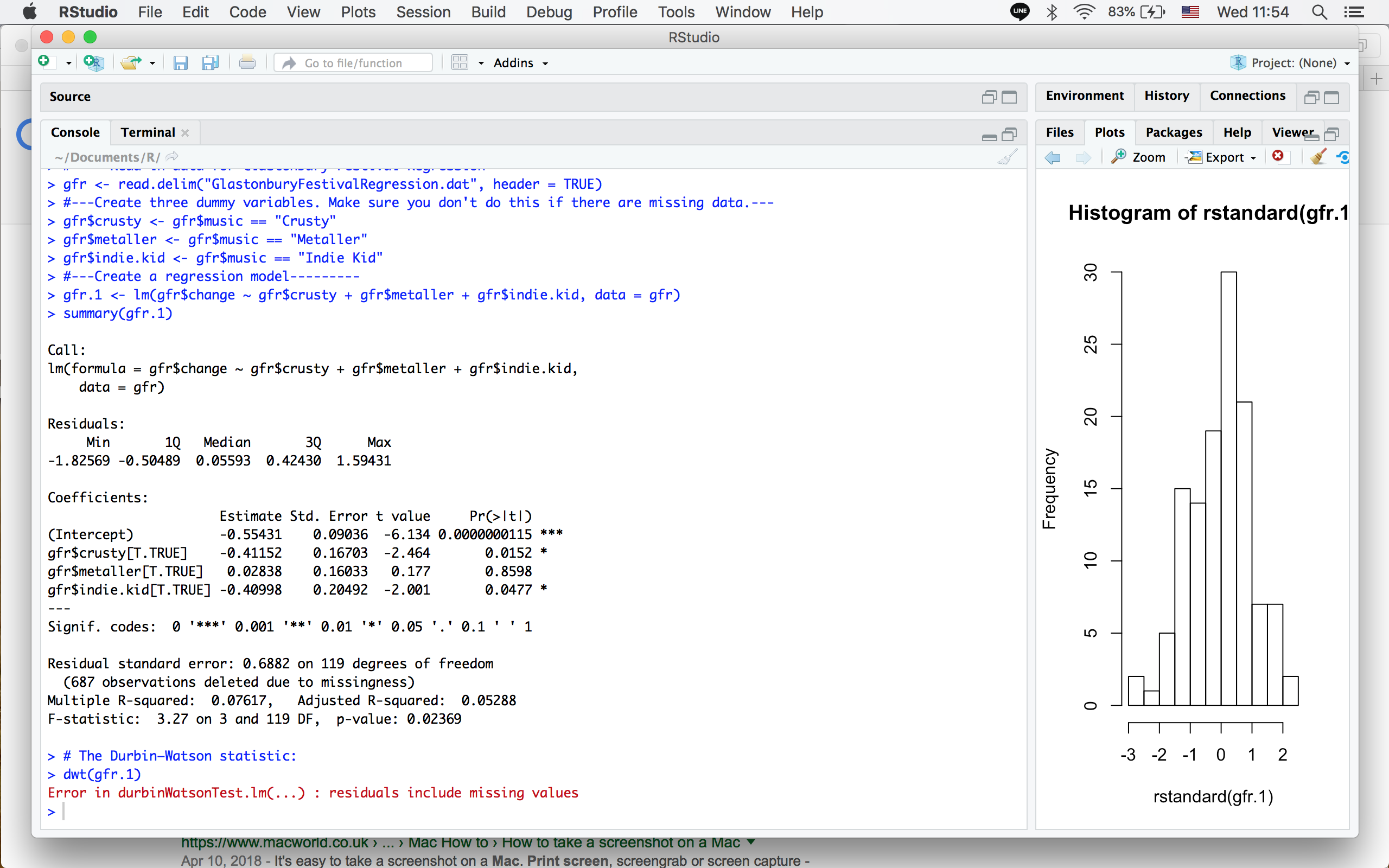
I am practicing on an example in my textbook, and an error occurred while I tried to do a dwt(), my codes are listed below:
Can anyone help with me? (I tried using na.action = na.exclude, but still the same error showed up.)
Thank you.
I am practicing on an example in my textbook, and an error occurred while I tried to do a dwt(), my codes are listed below:
Can anyone help with me? (I tried using na.action = na.exclude, but still the same error showed up.)
Thank you.
Could you please turn this into a self-contained reprex (short for minimal reproducible example)? That way we can be sure that we're looking at the same material, and no one has to go through the trouble of trying to type your code from a picture!
Right now the best way to install reprex is:
# install.packages("devtools")
devtools::install_github("tidyverse/reprex")
If you've never heard of a reprex before, you might want to start by reading the tidyverse.org help page. The reprex dos and don'ts are also useful.
If you run into problems with access to your clipboard, you can specify an outfile for the reprex, and then copy and paste the contents into the forum.
reprex::reprex(input = "fruits_stringdist.R", outfile = "fruits_stringdist.md")
For pointers specific to the community site, check out the reprex FAQ, linked to below.
I tried every step and I think I run into some problems. I'll try to figure it out.
I haven't figured out the problem yet, here is my codes, and I'll try to figure out what you showed me.
gfr <- read.delim("GlastonburyFestivalRegression.dat", header = TRUE)
gfr$crusty <- gfr$music == "Crusty"
gfr$metaller <- gfr$music == "Metaller"
gfr$indie.kid <- gfr$music == "Indie Kid"
gfr.1 <- lm(gfr$change ~ gfr$crusty + gfr$metaller + gfr$indie.kid, data = gfr)
summary(gfr.1)
dwt(gfr.1)
This is what I just got, and now the dwt() returns with no errors. I am even more confused.
gfr <- read.delim("GlastonburyFestivalRegression.dat", header = TRUE)
gfr$crusty <- gfr$music == "Crusty"
gfr$metaller <- gfr$music == "Metaller"
gfr$indie.kid <- gfr$music == "Indie Kid"
gfr.1 <- lm(gfr$change ~ gfr$crusty + gfr$metaller + gfr$indie.kid, data = gfr)
summary(gfr.1)
#>
#> Call:
#> lm(formula = gfr$change ~ gfr$crusty + gfr$metaller + gfr$indie.kid,
#> data = gfr)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.82569 -0.50489 0.05593 0.42430 1.59431
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.55431 0.09036 -6.134 1.15e-08 ***
#> gfr$crustyTRUE -0.41152 0.16703 -2.464 0.0152 *
#> gfr$metallerTRUE 0.02838 0.16033 0.177 0.8598
#> gfr$indie.kidTRUE -0.40998 0.20492 -2.001 0.0477 *
#> ---
#> Signif. codes: 0 '' 0.001 '' 0.01 '' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.6882 on 119 degrees of freedom
#> (687 observations deleted due to missingness)
#> Multiple R-squared: 0.07617, Adjusted R-squared: 0.05288
#> F-statistic: 3.27 on 3 and 119 DF, p-value: 0.02369
library(car)
#> Warning: package 'car' was built under R version 3.4.4
#> Loading required package: carData
library(carData)
vif(gfr.1)
#> gfr$crusty gfr$metaller gfr$indie.kid
#> 1.137931 1.143818 1.100084
1/vif(gfr.1)
#> gfr$crusty gfr$metaller gfr$indie.kid
#> 0.8787879 0.8742647 0.9090214
dwt(gfr.1)
#> lag Autocorrelation D-W Statistic p-value
#> 1 0.04948997 1.893407 0.534
#> Alternative hypothesis: rho != 0
reprex::reprex(input = "dwt_Question.R", outfile = "dwt_Question.md")
Ok, a few suggestions:
reprex runs in a new, isolated session, so if you’re getting different results that way, it’s a clue that it’s time to start fresh)x is NA, then x == “foo” will return NA, not FALSE, so any NAs in music are going to get propagated to your dummy variables. The lm summary is reporting over 600 cases that had to be excluded due to missingness.gfr using View(gfr) to make sure it imported correctly. If the NAs in music aren’t a mistake, then you may want to remove them before you create your dummy variables (whether doing so is a good idea or not depends on the nature of your data and the goals of your analysis).options("na.action") or did you apply na.exclude() to an object? If you check the docs, you’ll see that you probably wanted na.omit, rather than na.exclude, because:
na.excludediffers fromna.omitonly in the class of the"na.action"attribute of the result, which is "exclude". This gives different behaviour in functions making use ofnaresidandnapredict: whenna.excludeis used the residuals and predictions are padded to the correct length by insertingNAs for cases omitted byna.exclude.
lm uses naresid, so using na.exclude is going to add NAs to your residuals wherever data is missing (sometimes this is what you want!).
I’m on a tablet so I can’t run code right now, but I’ll check back in later — maybe by then somebody else will have chimed in with more (better) help anyway!
it works now as I recoded it.
(But I tried reprex, it tells me it could not find function vif, and dwt...)
gfr <- read.delim("GlastonburyFestivalRegression.dat", header = TRUE)
gfr <- gfr[complete.cases(gfr), ]
gfr$crusty <- gfr$music == "Crusty"
gfr$metaller <- gfr$music == "Metaller"
gfr$indie.kid <- gfr$music == "Indie Kid"
gfr.1 <- lm(gfr$change ~ gfr$crusty + gfr$metaller + gfr$indie.kid, data = gfr)
summary(gfr.1)
Call:
lm(formula = gfr$change ~ gfr$crusty + gfr$metaller + gfr$indie.kid,
data = gfr)
Residuals:
Min 1Q Median 3Q Max
-1.82569 -0.50489 0.05593 0.42430 1.59431
Signif. codes: 0 '' 0.001 '' 0.01 '' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.6882 on 119 degrees of freedom
Multiple R-squared: 0.07617, Adjusted R-squared: 0.05288
F-statistic: 3.27 on 3 and 119 DF, p-value: 0.02369
vif(gfr.1)
gfr$crusty gfr$metaller gfr$indie.kid
1.137931 1.143818 1.100084
1/vif(gfr.1)
gfr$crusty gfr$metaller gfr$indie.kid
0.8787879 0.8742647 0.9090214
dwt(gfr.1)
lag Autocorrelation D-W Statistic p-value
1 0.04948997 1.893407 0.558
Alternative hypothesis: rho != 0
Glad you found a solution! 
As for reprex, it runs the code you give it in a completely new session and environment, so you have to make sure to include all the necessary library() calls in the reprex-ed code, and make sure every object you reference is created inside the reprex-ed code. This helps ensure that the reproducible example really is self-contained and reproducible by anybody else.
So in your case, you'd want to make sure that the code you are trying to turn into a reprex has library("car") at the beginning.
Thank you so much for explaining it to me. I really appreciate it.
I am glad I learn something new from this problem.