In this SO answer, I leverage other tidyverse packages to make scraping a little more robust (with RETRY in case of failure) and a little more gentle on the server (with basic Sys.sleep() calls): https://stackoverflow.com/questions/43218761
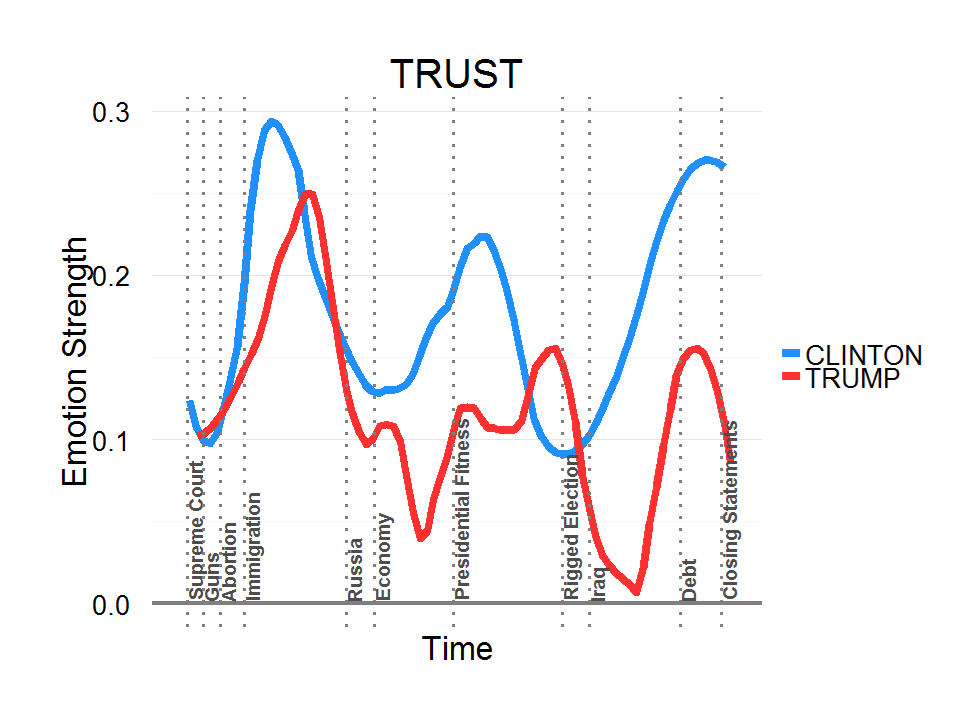
Not the most interesting probably, but I found it incredibly useful for the "Media and Politics" class I taught during the 2016 US presidential campaign. I used it to to scrape debate transcripts and news stories, providing objective data to supplement/challenge students' personal perceptions of news coverage and bias.
And I found Julia Silge and David Robinson's book very useful for this endeavor.
I needed to scrape lots of tables of public health data, many tables recognized by their headers, in sub-sub pages
most interesting were solutions proposed to me on StackOverflow:
In one case I needed RSelenium to help rvest find its way (java dropdown invisible in html):
Well. Here is a function that brings down all public shares traded at any specified market run by NASDAQ OMX Nordic and also sorts out the hyperlinks included in a couple of the HTML-table columns. But it is not from the wild, it is from my C-drive.
I've never used rvest but I'm hoping to learn how to use it so that I can scrape NHL scores from nhl.com daily to save me some time. I use the scores for an ELO based prediction model on a game by game basis, similar to what FiveThirtyEight does with baseball. Not terribly unusually but it is a very fun project to work on.
It isn't written up anywhere, but someone recently told me that cried tears of joy when I explained how for the dozens of organisational policies they were responsible for updating which only existed on the web, they could use rvest to assemble local copies and build a tabular arrangement of the metadata like original author & date due to be updated.
I'm only part way through the project, but I'm using it to scrape an online booking site for court availability at my local sport club at select times. If the court I want is free, it can then book it for me. The blue-sky plan is to then integrate with Twilio to send me a text to confirm the booking!
I'm using rvest in a way similar to @eric_bickel, to scrape Berkeley Earth temperature data. I scrape the links for countries from their HTML table, download the data and then match it with countries in other datasets using @drob's fuzzyjoin (although admittedly matching country names is not a great use for that package). It needs a lot more time in the oven, but I'm documenting the experiments as I go
For standardizing country names, I recommend trying the countrycode package, which comes with a set of regexes for recognizing country names.
You can convert them into 2 character codes (then join on those) with:
library(countrycode)
cnames <- c("United States", "United States of America", "South Korea", "Korea, South")
countrycode(cnames, "country.name", "iso2c")
Though if you'd like to use fuzzyjoin, you can also use regex_inner_join() to join with countrycode::countrycode_data on the country.name.en.regex column. Good luck!
Yeah, I found that trying match country names with fuzzyjoin was difficult, since most of the algorithms are always going to preference words with substituted letters (eg. Ireland against Iceland) over phrases that are supersets of others ("United States of America" against "United States"). I didn't know that countrycode has regexes, though, so I'll check that out!
This is pretty cool! To expand it more, how can you add random user agent data (Mozilla, Chrome, IE etc) to that safe_retry_read_html function? Thank you!