Excited to see the follow up post as well. Honestly it'd be great to see the growth for analysis specific tags like pandas, dplyr etc. I have a feeling that may put the R and Python comparison on a slightly more comparable scale. There has been a lot of growth in both languages and the two seems to be borrowing from one another, which is great in my opinion.
I actually agree with you in general. But, I also don't see Bayesian modelling in the big data world. Yes, there is Bayesian deep learning, but I don't know how much of that is actually done at the moment.
When you are doing ML, you sometimes work with black-box problems, so you don't even have a prior belief. Or, in the statistics world, it's the nonparametric model, essentially it has "distribution free" assumption.
In ML, your data is big, but not massive. Think of training SVM vs. neural network. You don't see performance gain on smaller datasets. When it's massive, that's where you see performance gain.
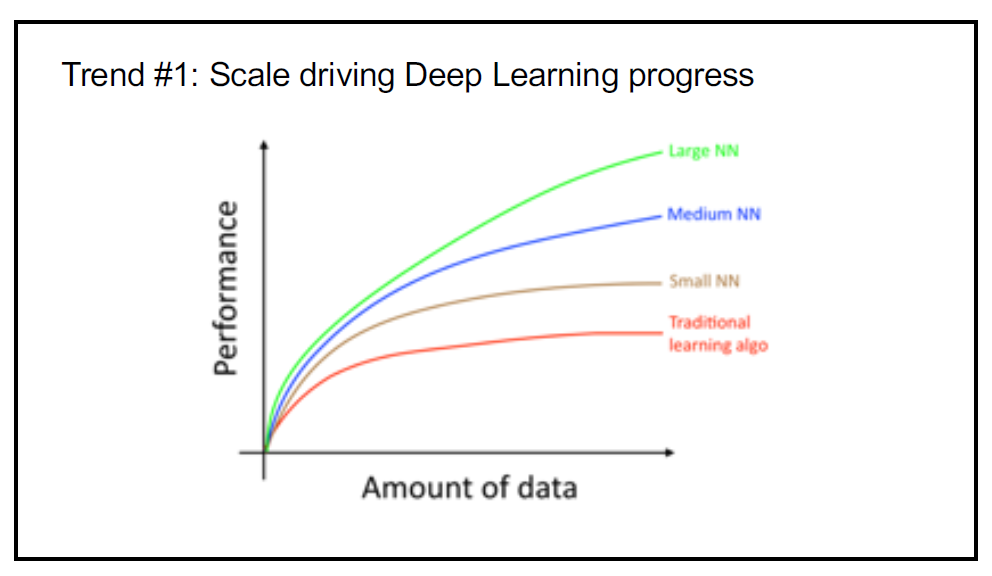
Yann LeCun gave a talk not too long ago where he showed the difference between learning algorithms. I can't find it.
Facebook and Google are also both using R. Python is a first class language at Google, meaning they are allowed to use it for many new projects. R is a widely accepted language at Google for data analysis and research. I'm not a Google employee, but I know some and was told this information directly from them. I knew much fewer people at Facebook, but it seems to be a similar policy -- python is accepted for most data science "production" work and R is fine for research and analysis.
1 Like
While I want to champion R because:
- it is not slow (your code is slow... not problem of the language)
- it is perfectly usable as a production language (thanks Docker + packrat)
- programming in R today is very different than programming in R 3 years ago (thanks tidyverse, caret, and data.table), though that argument could also be made for python it is much less different
I really love R. I get to use it as a production language at my day job and I prefer it over python for most data science tasks.
All that said, I'd say 80-90% of the data scientist interviews (~20) I've gone through over the past 2 years have made it clear during the interview that while it is fine that I prefer R, they would want me to use python at their company. I firmly believe this is due to misconceptions and lack of caring about doing due diligence, but it still means using python is usually going to be easier for employers to accept.
I have job subscriptions to various job boards and every once in a while I compile the results and check the trends. I've found data engineering roles using python to be growing a lot faster and more common than data science jobs using python, with a similar level of difference between python data science and R data science. This may also be due to python being unique to jobs and very common in generic software engineering roles (since what software engineer doesn't deal with data?), while R is a single letter and harder to parse.
7 Likes
The other comment I'd like to interject here is that R isn't just "data science". While it definitely isn't a great general purpose language, and is likely never going to beat out Python for writing a custom web server, it is an excellent statistics language. No question that there is overlap in the needs between data science and statistics, but for those of us that spend a lot of time on "small data", ease of use, ready access to well-understood statistical methods, and a great method of reporting beats speed hands-down.
I'm not saying that Python can't do those things, but R does them extremely well, and focusing entirely on large-scale data science-y problems loses some of the larger picture.
6 Likes
I wouldn't worry too much about this. Look at it as a classic Tortoise and Hare clash. Python might have the edge in a few niches that are growing quickly right now, but I would argue R is stronger in more stats/data science niches than Python. Python advocates point to R's "fractured" ML library niche, but the same could be said about Python visualization and reporting. R also has a really good suite of tools for addressing performance issues at a low level - Rcpp is an amazing asset that probably doesn't get a lot of recognition outside of R.
All we have to do to ensure the longevity and ultimate superiority of R for Data Science is keep contributing ideas and code that make our lives easier and more enjoyable. Python's broad usecases are actually a liability since they pull the community in many directions.
4 Likes
Yes, I do agree that R is great for "small data" analysis for sociology and psychology. And if you are doing social science in general, R is great. Time series fitting ARMA and ARIMA, R is also much better.
More concretely, packages such as MI and amelia for missing data. Tidyverse for presentation, code clarity and consistency are obvious. If you are doing hierarchical modelling, then lme4, lmer is great. And more recently, you have STAN.
ggplot2 for visualization is pretty much agreed by Python users, too.
I really saw the hay day of R in ML when packages such as glmnet came out.
I totally agree with you. There are some people that even don't know the existence of the tidyverse. And about the performance for data manipulation I think nothing is faster than data.table (if we focus on open source world). But I believe that R comunity should do more for what concerns "deep learning & friends".
TensorFlow in R is slow?
I usually use R for data manipulation and use python for ML.
feather library is good file extension to connect those two language,
but I wish the wrapper of scikit-learn like tensorflow or keras 
2 Likes
I agree. R for data manipulation, and Python for ML and DL. From what I've heard, if you are doing webscraping for data, then beautiful soup is also fine. Then, your chance of switching to R is limited.
Where is Julia-lang at the moment? Is anyone using that?
I talk to people who use Julia, they love it! I don't use it myself.
After a quick Goolging, here's one from Julia. Looks pretty cool!
Yes, there's also Scala, lisp, Ruby, and the list goes on...
It looks like the post was actually published shortly before you wrote that, @rkahne.
David provides a reasonably convincing argument that most of the growth of Python is due to data science application. The conclusion is particularly applicable to this discussion:
Now we can look forward to the next follow-up post!
4 Likes
I saw that today! It was featured in the Data Elixir newsletter. I'm interested to read his R v. Python post. He's a good writer with good perspective.
Regarding "It could be a bunch of grad students using R for course requirement": interestingly, we can get a better view of this using internal Stack Overflow data.
Just as I analyzed the industries Python was visited from in this blog post, we can analyze the industries R is visited from in 2016-2017.
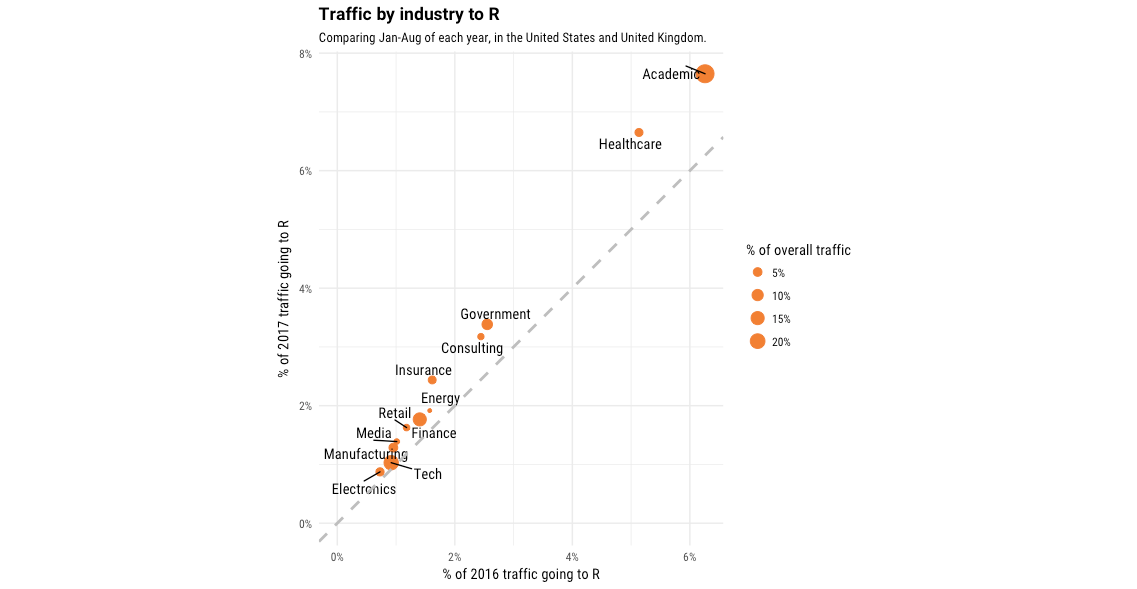
R is growing in many sectors, and indeed the area where it is both largest and shows the most growth is from universities. However, it is nearly as large and showing a similar degree of growth in the health care sector, and is also growing in visits from government, consulting, and insurance firms.
Having said that, one area where it is still relatively underrepresented, and staying at a generally similar size from 2016 to 2017 (at 1% of question views), is tech (software and web companies). This is in contrast to Python, which was growing basically everywhere, even in areas like retail and insurance where it made up a smaller % of traffic. This may therefore fit a story of R becoming very popular for data analysis across many fields, but not particularly growing for machine learning in production-focused environments.
12 Likes
That's great insight! Hopefully, R will step up in its ML/DL game.
R has grown more horizontally than vertically over the years. I don't think it's best use of time and resources.
Python really thrived because it focused on implementing the latest machine learning algorithms or whatever is current.
1 Like
I think that one of the major point here is that people that in general use C-like languages are more familiar with the python syntax than the R one.
2 Likes
That's interesting. I felt the way Python object-oriented programming is different, even if you know R, it doesn't always help.
In R, everything is assigned to an object
model <- lm(y~x, data = dat)
In Python, you don't always need to assign results to an object,
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
It can be confusing sometimes. Line 3 fits a linear regression, what if you don't remember you actually ran line 3 already.
R functions can modify their arguments, but it is typically discouraged (/not particularly easy), and the tidyverse in particular generally tries to follow the functional programming mantra of not having side effects. That said, you could make a new style of formula (like y %~% x) that adds residuals to the parent data frame when you run lm. It just wouldn't be very R-like.