Hi Gilles, it's hard to figure out why you have problems to get your names of interest. A reprex would make it may more easy for us! Please, try to use 'reprex' (FAQ) in future. It's a cool tool to post your questions to the R-communtiy. It helps us to help you! ![]()
As Kamil mentioned the broom package gives you a nice and easy way to summaries or handel different model objects.
Below you will find a solution similar to your code (without the use of the broom package, but I would try broom if you have to handle different model types)...
library(gplots)
#calculate anova example (see aov() help...)
npk.aov <- aov(yield ~ block + N*P*K, npk)
#get anova model summary
npk.summary <- anova(npk.aov)
npk.summary
#> Analysis of Variance Table
#>
#> Response: yield
#> Df Sum Sq Mean Sq F value Pr(>F)
#> block 5 343.29 68.659 4.4467 0.015939 *
#> N 1 189.28 189.282 12.2587 0.004372 **
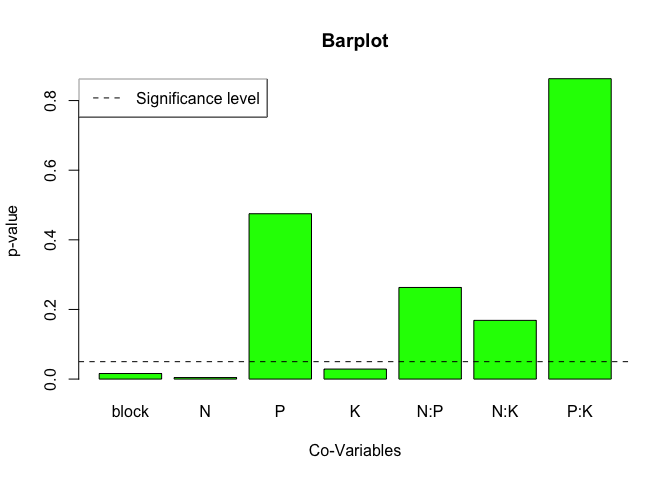
#> P 1 8.40 8.402 0.5441 0.474904
#> K 1 95.20 95.202 6.1657 0.028795 *
#> N:P 1 21.28 21.282 1.3783 0.263165
#> N:K 1 33.13 33.135 2.1460 0.168648
#> P:K 1 0.48 0.482 0.0312 0.862752
#> Residuals 12 185.29 15.441
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#drop residual information for barplot2 visualization
# as hint: the anova object can be handled like a data frame, because it is one! :)
fig.data <- subset(npk.summary, !rownames(npk.summary) %in% 'Residuals')
fig.data
#> Df Sum Sq Mean Sq F value Pr(>F)
#> block 5 343.29 68.659 4.4467 0.015939 *
#> N 1 189.28 189.282 12.2587 0.004372 **
#> P 1 8.40 8.402 0.5441 0.474904
#> K 1 95.20 95.202 6.1657 0.028795 *
#> N:P 1 21.28 21.282 1.3783 0.263165
#> N:K 1 33.13 33.135 2.1460 0.168648
#> P:K 1 0.48 0.482 0.0312 0.862752
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#show rownames or colnames
rownames(fig.data)
#> [1] "block" "N" "P" "K" "N:P" "N:K" "P:K"
colnames(fig.data)
#> [1] "Df" "Sum Sq" "Mean Sq" "F value" "Pr(>F)"
#plot your stats of interest
Title <- 'Barplot'
barplot2(height = fig.data$'Pr(>F)', xlab = "Co-Variables", ylab = "p-value",
main = Title, col = "green", names.arg = rownames(fig.data))
#add your level of significance
abline(h=0.05, lty=2)
#add legend
legend('topleft', 'Significance level',lty=2)
Created on 2019-02-14 by the reprex package (v0.2.1)